
- Today
- Total
Byeo
Toward microsecond Tail Latency and Terabit Ethernet: Disaggregating the Host Network Stack 3 본문
Toward microsecond Tail Latency and Terabit Ethernet: Disaggregating the Host Network Stack 3
BKlee 2023. 12. 16. 20:46이 포스트는 sigcomm 22의 NetChannel [https://dl.acm.org/doi/pdf/10.1145/3544216.3544230] 를 번역하여 정리한 글입니다.
구현과 실험은 짧게 요약만 하고 넘기려고 합니다! 관심이 있다면 직접 읽어보시길 추천합니다.
4. 구현
구현 환경: Linux Kernel v5.6, 기존의 Linux kernel source code를 최대한 활용
Application interfaces: 애플리케이션의 코드가 최대한 수정되지 않도록 함을 목표, 기존 Kernel의 socket API에서 IPPROTO_VIRTUAL_SOCK flag와 setsockopt()를 통해 여러 설정들을 변경할 수 있도록 구현
Virtual socket connections: 기존 socket API와 유사하게 두 호스트간 연결이 생성됨: client가 connect를 걸어서 server의 listen중인 socket으로 연결 수립. server의 accept 시스템 콜이 fd를 반환. 내부적으로 NCSYN과 NCSYN_ACK을 통해서 handshake 수행.
NetChannel headers: 하나의 virtual socket이 여러 channel을 사용할 수 있고 혹은 여러 virtual socket이 하나의 channel을 공유할 수 있음에 따라, NetChannel은 packet의 payload 앞에 추가적인 헤더를 붙여서 virtual socket을 구분. header는 다음을 포함한다.: (1) virtual socket의 source와 destination port, (2) packet reordering을 수행하기 위한 virtual socket 내의 sequence number, (3) control packet을 구분하기 위하여 packet type
Reducing page allocation overheads for DMA: DMA의 page 할당 오버헤드를 줄이기 위해서, NIC의 receive queue를 위해 존재하는 별도의 page pool을 구현. 다만 너무 많은 페이지 조기 할당은 L3 cache miss를 증가시켜 DCA 효과를 약화시키기 때문에, 256개의 page만 사용하도록 하였다. NIC은 256개의 Rx queue를 갖고 있었기에, 256 (Rx-queue) * 256 (pages) * 4KB (page size) = 256 MB 라서, 그 공간의 부담이 크지 않다.
Scheduling policy: application data를 channel로 보내는 과정과, data copy worker는 모두 round-robin 으로 처리. (1)과 (2) 각각은 실험적으로 결정된 2MB, 640 KB 단위로 처리됨. Channel/worker overload를 피하기 위해서, 처리해야 할 queue의 사이즈가 특정 threshold를 넘는 channel과 worker는 배제하였다.
5. 실험
실험을 통해서 증명하고자 하는 내용:
1. NetChannel은 새로운 운영 방식을 제공할 수 있음 (스택을 쉽게 개발해서 integration 가능)
2. 그러면서도 기존 Linux가 달성할 수 없었던 200 Gbps를 단일 socket 만으로도 처리할 수 있음을 보임
3. 사용하는 Core의 개수에 비례하면서 short message throughput이 증가가 가능함을 보임
4. T-apps와 L-apps가 공존하는 상황에서도 L-apps가 micro second-scale latency가 유지 가능함을 보임
인지할 점:
1. application 수정이 필요가 없다. NetChannel 위에서 쉽게 application을 구동시킬 수 있다.
2. Netchannel은 SOTA network stack의 성능을 이길 수 있음을 보이려는 것 보다는 NetChannel의 구조와 오버헤드를 분석하는 것에 초점이 있다.
3. 단일 core의 성능 향상은 오랜기간 이루어지지 않고 있기 때문에, multiple core를 사용하는 것은 필수적이다. NetChannel은 packet processing을 여러 코어에 병렬을 처리하는 과정에서 약간의 CPU overhead가 추가된다.
5.1 실험 셋업
2개의 서버
CPU: Intel Xeon Gold 6234 3.3 GHz CPU
CPU: 4 NUMA nodes, NUMA node당 8 코어. (실험은 CPU core의 NUMA가 NIC NUMA와 동일한 곳에서 실행되도록 구성)
CPU L1/L2/L3: 32KB/1MB/25MB
DRAM: 384GB
NIC: Mellanox ConnectX-5 NIC 100 Gbps, 두 서버는 곧바로 연결됨 (스위치를 거치지 않음)
OS: Ubuntu 20.04 (Linux kernel 5.6)
Enabled options: TSO, GRO, Jumbo Frames, aRFS, Dynamically-Tuned Interrupt Moderation (DIM), DCA (Intel DDIO)
Disabled options: Hyperthreading, IOMMU
Workloads
T-apps: iperf, L-apps: 4KB ping-pong style requests/responses RPC
standard read/write systemcall vs io_uring
Test applications: Redis, SPDK
Performance metrics
T-apps: throughput (Gbps), L-apps: 99.9 percentile tail-latency
CPU Efficiency: throughput-per-core (throughput / CPU utilization, CPU utilization = Tx 혹은 Rx side CPU 사용량 중 최대값)
5.2 New Operating Points

Scalability for long flows.
Figure 6(a): 기존 Linux는 가용할 수 있는 CPU가 더 있음에도 불구하고 single T-apps가 100 Gbps를 달성할 수 없다. 반면에 NetChannel은 2개의 별도 data copy thread를 사용하여 기존의 read/write system call로도 100 Gbps 달성 가능하다.
Figure 6(b): figure 6(a) 상태에서의 CPU 사용량을 보여준다. NetChannel은 data copy 작업을 VNS에서 scaling할 수 있게 함에 따라 더 많은 CPU를 착취할 수 있는 것이다. (NetDriver 계층에서 1개의 channel, 2개의 data copy threads)
io_uring은 NetChannel 위에서 동일하게 multicore CPU를 사용해 100 Gbps를 달성할 수 있다.
Scalability for short messages.
(해당 실험에서는 network layer processing을 지배적(dominant)으로 만들기 위해서 TSO/GRO, jumbo frame 비활성화)
4KB RPC 실험 결과, NetChannel은 data가 signle virtual socket에서 여러 Channel로의 multiplexing을 허용함으로써 자유롭게 네트워크 계층의 처리를 스케일링할 수 있음을 보였다.
Figure 6(c): 표준 read/write system call로도 channel의 개수에 정비례하여 전체 throughput이 증가함을 확인할 수 있었다. io_uring도 마찬가지. (단, io_uring이 표준 read/write system call보다 성능이 조금 낮은 이유는 io_uring 자체의 overhead때문)
Enabling performance isolation.
T-app와 L-app의 간섭을 실험하기 위하여 8개의 CPU core 위에서 8개의 T-apps와 1개의 L-app을 구동
Figure 6(d): 기존 Linux stack (빨간색 막대)는 간섭시에 상당한 tail latency 증가를 보인다. NetChannel은 L-app과 T-apps가 같은 CPU core위에 있더라도 L-app의 네트워크 계층 처리를 T-apps로부터 'channel'을 격리시킬 수 있다. 그리고 그 channel을 다른 CPU core로 매핑시킬 수 있다. 그래서 그 결과 6(d)처럼 NetChannel의 경우에 기존 Linux보다 17.5x 낮은 tail latency를 확인할 수 있었다.
5.3 NetChannel Overhead
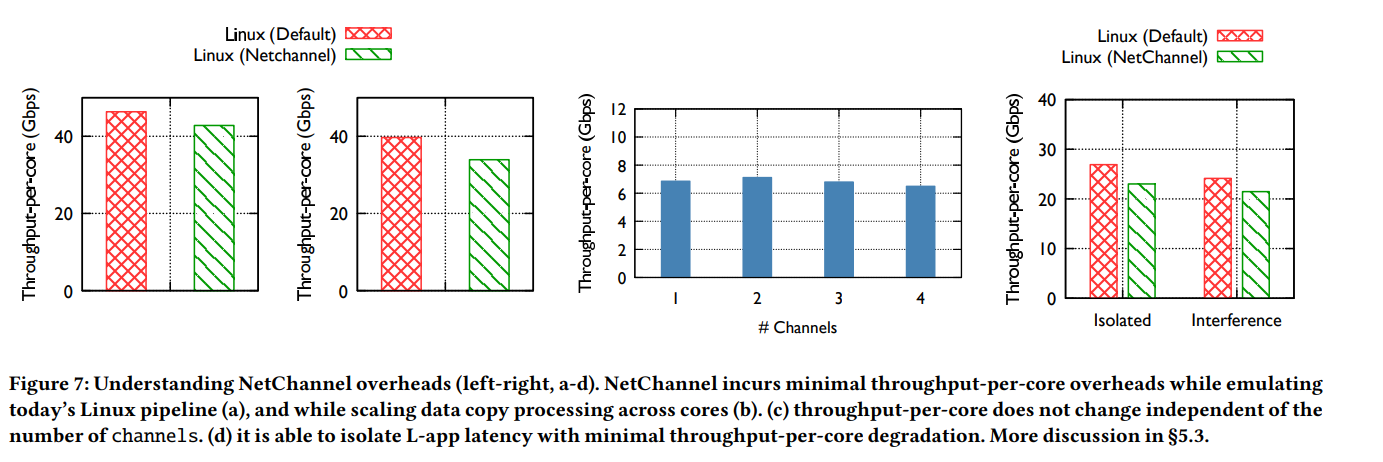
Overheads of emulating the Linux network stack.
Figure 7(a): NetChannel이 가져다주는 기본적인 overhead를 비교하기 위해서 하나의 CPU core 위에 단일 thread의 애플리케이션과 단일 channel을 실행시켰다. 반대로 Linux도 단일 thread를 실행하여 비교했을 때, NetChannel의 오버헤드는 throughput-per-core metric에서 최대 7%였다. 두 시스템 모두 병목은 Rx-side였다. (aRFS 활성화)
Overheads of scaling data copy processing.
Figure 7(b): Linux 기존 stack과 NetChannel 모두 3개의 CPU core를 사용하여 비교한다. Linux는 3개의 application이 동시에 Tx를 하여 100 Gbps link를 채우는 상황을 구성하였고, NetChannel은 2개의 copy worker thread와 1개의 channel을 이용하여 100 Gbps link를 채우는 상황을 구성해 비교하였다. NetChannel이 12%의 throughput-per-core 효율 손실을 보였으며, 이는 L1 cache가 warm이 아니어서 발생한 비용이다. (Application thread와 copy thread는 필연적으로 최소 하나는 다를 수 밖에 없을 것이다.)
Overheads of scaling network layer processing.
Figure 7(c): Network layer의 처리를 scaling하는 과정에서의 overhead를 비교하기 위해 channel을 점차 늘려나갔다. 기존 Linux에 비해 굉장히 적은 throughput-per-core 효율 감소를 보인다. 미세하게 감소하는 부분은, channel이 늘어날 수록 NetScheduler가 조금 더 빈번하게 작업을 처리해야 하기 때문. (논문은 이를 최소화 하기 위한 solution으로 batching을 idea를 제안한다.)
Overheads of achieving performance isolation.
Figure 7(d): 8 T-apps와 1 L-app를 구분해서 실행하여 L-app의 latency를 보존하는 과정에서도 굉장히 적은 overhead를 야기하였다.
5.4 Real-world application with NetChannel
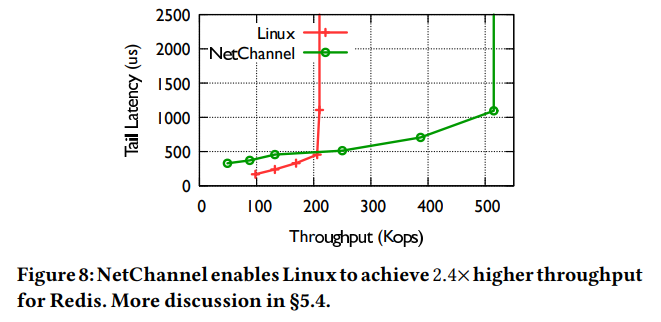
Redis with NetChannel.
표준 YCSB workload를 실행 (read / write = 95% / 5%). 각 RPC는 4KB.
Figure 8은 NetChannel 위에서 및 그렇지 않은 환경에서의 latency-throughput curve를 보여준다. NetChannel은 2.4x 더 높은 throughput을 보였다. 이는 여러개의 channel을 사용해 network layer processing을 잘 scaling했기 때문. (이 실험에서는 4개의 channels가 활성화 됨)
Latency의 경우에는 throughput이 낮을 때 기존의 Linux보다는 조금 높은 latency를 보인다. 이는 scheduling 및 reordering latency 때문. 해당 비용은 latency가 낮을 때 상대적으로 잘 확인할 수 있으며, 그 비용은 대략 160 us 정도이다.
SPDK-based remote storage stack with NetChannel.
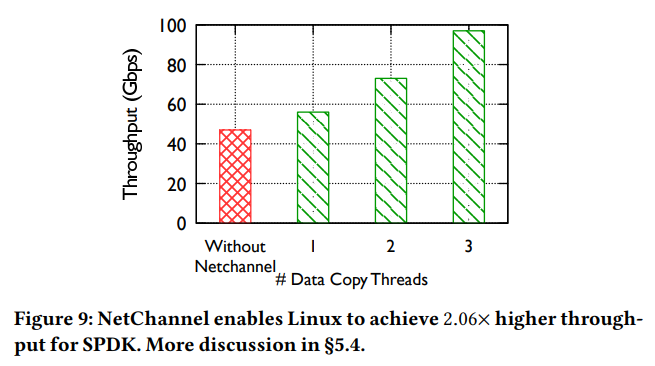
SPDK의 NVMe-over-TCP stack (기존 Linux TCP stack을 사용해 remote storage device를 접근)을 사용했을 때의 성능을 비교하였다. Client와 server의 application은 단일 CPU 위에서 실행되며, 1개의 TCP 연결만을 수립하였다. NetChannel을 사용하기만 해도 기존보다 약 1.19배의 throughput 향상을 보인다. 이는 network layer processing이 다른 core에서 별도로 진행되기 때문 (그러면 스택에서 사용된 CPU 개수가 다르다는 의미 아닌가?). Copy thread를 늘려 각기 다른 CPU Core에 배치하면 성능 향상이 점점 더 증가한다. (6(a)와 비교했을 때SPDK는 100 Gbps를 달성하기 위해서 1개의 추가 copy thread가 필요하다고 한다. 이는 SPDK가 더 큰 buffer (2MB)를 사용하고, application logic이 조금 더 붙기 때문. 이 두 가지 요소가 더 높은 L3 cache miss rate를 발생시켰다.)
5.5 NetChannel with Terabit Ethernet
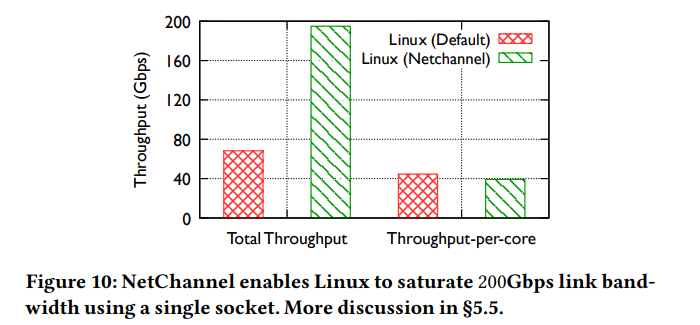
이 실험에서는 200 Gbps를 낼 수 있는 ConnectX-6 NIC을 사용하였다. 각 NUMA당 18개의 cores를 지니고 39MB L3을 갖고 있는 Intel Xeon Gold 6354 3.0GHz CPU를 사용. 1개의 T-apps를 실행.
Figure 10: 2개의 channels와 3개의 data copy thread를 사용했을 때, 단일 application도 200 Gbps를 달성할 수 있음을 확인. (100Gbps를 넘기려면 2개의 channel을 요구한다!). Throughput-per-core 효율은 NetChannel과 Linux가 유사. 다만, 둘다 기존 환경보다 throughput-per-core 효율이 증가했는데 ( 연산: figure 6(a) / figure 6(b) ), 그 값은 w/o , w/ NetChannel이 각각 12%, 15%이다. 그 이유는 L3 cache size가 증가하여 data copy 효율이 개선되었기 때문.
6. Discussion
Can NetChannel architecture be applied to other network stacks?
해당 논문에서는 Linux network stack을 대상으로 삼고 비교하였다. 하지만 NetChannel은 userspace 또는 hardware로의 구현도 가능하다. 마이크로 커널 스타일의 userspace stack도 NetChannel의 구현을 따라 이득을 얻을 수 있으며, TAS와 같이 packet processing pipeline을 application core에서 이미 분리시킨 work도 NetChannel의 추가적인 disaggreagtion을 통해 더 이득을 얻어낼 수 있다.
NetChannel은 많은 수의 wimpy core (약간 성능이 떨어지는)를 지닌 SoC smartNIC도 transport-agnostic (TCP 말고도 다양한 protocol들을) parallelization을 달성할 수 있을 것이다. 또한, data copy thread의 작업을 별도의 CPU core가 수행하는 것이 아니라 I/OAT와 같은 특수 hardware에게, 그리고 Tonic과 같이 transport layer를 NIC offload 하는 식으로 분리하는 식의 더 나아간 확장이 가능할 것이다.
Can NetChannel benefits be achieved with modifications outside the network stack?
NetChannel과 같은 구현체를 외부 라이브러리로서 사용을 하면 어느정도 이득을 볼 수 있겠지만, 다음과 같은 두 가지 한계점이 존재한다. (1) packet 처리의 다양한 부분을 분리하고 독립적으로 scaling 하는 데는 Linux stack의 수정을 필요로 한다. (2) 멀티 테넌트 환경에서는 이 라이브러리가 모든 애플리케이션이 실행되는 현 시스템의 상황 (CPU 사용량 등)을 확인할 수 없다.
NetScheduler policies.
NetChannel의 스케쥴러는 다양한 정책들을 쉽게 도입할 수 있도록 확장성을 제공한다. 실험에서 사용된 가장 간단한 스케쥴링 기법만으로도 상당한 성능 향상을 보였으며, 앞으로 수년에 걸쳐 애플리케이션의 특성에 맞는 새롭고 진화된 기법이 등장하리라 기대한다.
7. 관련 연구
Linux network stack improvements.
기존 Linux TCP zerocopy 기법은 존재하지만 (MSG_ZEROCOPY, mmap_recv), 완벽한 해결책이 아니다. 특히 mmap_recv와 같은 경우에는 한계가 있어서 널리 적용되지 못하고 있다.
그 외의 다양한 최적화 (새로운 interface, system call, socket implementation) 기법들과 NetChannel은 상호 보완적이다.
Userspace network stacks.
최근에 많은 work들이 DPDK와 netmap 위에서의 network stack을 구현했는데, NetChannel도 Linux Stack에 말고도 userspace에 구현함으로써 접근 가능한 방법중에 하나이다.
Hardware network stacks.
TCP stack을 hardware에 구현한 작업들이 많이 존재한다. 컨셉상으로는 FlexTOE가 NetChannel과 많이 가깝다. 하지만 이는 TCP에만 집중을 했고, end-to-end packet 처리 파이프라인을 application부터 NIC까지, 그리고 transport layer가 무엇이든지에 상관없이 구성할 수 있도록 한 NetChannel과는 차이가 있다.
8. 결론
우리는 오늘날의 network stack이 dedicated, tightly integrated, and static 한 packet processing pipeline을 지니고 있어서 하드웨어의 성능을 최대한 활용할 수 없는 상황에 도달하였다. NetChannel은 기존의 network stack을 약하게 연결된 3개의 계층 구조로 분리하였다. 이러한 구조를 채택함으로써 기존에 달성할 수 없었던 1 application 만으로의 Terabit ethernet link speed, network layer processing의 자유로운 scaling, L-app과 T-apps의 performance isolation 이 가능함을 증명하였다.



