
- Today
- Total
Byeo
Toward microsecond Tail Latency and Terabit Ethernet: Disaggregating the Host Network Stack 2 본문
Toward microsecond Tail Latency and Terabit Ethernet: Disaggregating the Host Network Stack 2
BKlee 2023. 11. 13. 23:29이 포스트는 sigcomm 22의 NetChannel [https://dl.acm.org/doi/pdf/10.1145/3544216.3544230] 를 번역하여 정리한 글입니다.
이 논문은 이전에 정리했던 sigcomm 21의 Understanding Host Network Stack Overheads 논문의 후속 논문이라고 볼 수 있습니다.
2. Motivation
이 섹션에서는 오늘날의 host 네트워크 스택이 여러 방면에서 비효율적임을 증명한다. 실험에서는 리눅스 커널의 TCP뿐만 아니라, MPTCP (Multi-Path TCP), 다양한 인터페이스 (e.g., 표준 read/write, io_uring), 다양한 packet 처리 최적화 기법 (e.g., packet coalescing, packet steering), 그리고 다양한 격리 기법들을 비교한다.
우리의 중요한 발견 요소는 다음과 같다:
- Static and dedicated packet 처리 파이프라인은 애플리케이션으로 하여금 host CPU를 최대한 사용하는 것을 못하게 한다. 모든 최적화 기법을 동원해도, single TCP long flow는 100 Gbps를 도달하지 못한다 (최대 60 Gbps까지 가능함을 확인하였다.) (근데 어떻게 60이 나왔지? 내 경험보다 많이 높은데, 차이가 무엇인지 따로 찾아봐야겠다.). 60 Gbps 상태에서는 rx-side의 CPU가 병목이 되었고, 오늘날의 네트워크 스택은 이를 동적으로 늘리거나 줄일 수 있는 기능을 제공하지 않는다. MPTCP도 다를 바는 없다. 어차피 multi path를 사용하여 TCP path의 개수를 늘리더라도, 결국 host의 single CPU core가 병목인 문제는 변함이 없기 때문.
- Static and dedicated packet 처리 파이프라인은 Linux로 하여금, RPC와 같은 short message를 처리하느라 네트워크 계층이 병목이 된때에 connection의 개수를 동적으로 늘리거나 줄이는 것을 불가능하게 한다. MPTCP는 여기서도 또한 같은 이유로 스케일링에 실패한다.
- Tightly-integrated packet 처리 파이프라인의 태생은 latency 민감 애플리케이션(L-apps)과 Throughput를 많이 쓰는 애플리케이션(T-apps)가 공존할 때, 성능 격리를 시키기 매우 어렵다. 만약 L-apps와 T-apps가 코어를 공유하면, 오늘날의 네트워크 스택은 L-app과 T-app 사이에서 packet처리를 중재해줄 매커니즘이 존재하지 않는다. 결국 HOL blocking에 의해 L-app의 tail latency가 급증하는 결과 (실험했을 때 37배까지 관찰)를 낳는다.
2.1 실험 환경
- 100 Gbps로 연결된 2개의 서버
- 각 서버는 4 NUMA node를, 그리고 각 NUMA node당 8개의 CPU core를 포함하고 있다.
- DCA (Intel DDIO) 활성화하였고, L3 cache way를 최대한 사용하였다.
- TCP 실험에서는 Linux Kernel v5.6을 사용하였다. MPTCP 실험에서는 MPTCP kernel v0.95를 사용하면서 subflow의 개수를 수동적으로 늘렸다.
- T-apps로는 iperf를, L-apps로는 4KB message ping-pong style RPC를 사용하였다.
- T-apps의 throughput-per-core와 L-apps의 99.9 percentile tail latency 측정하였다.
2.2 현 커널 스택의 한계
(1) Static and dedicated pipeline: long flows에 대하여 scalability 부족

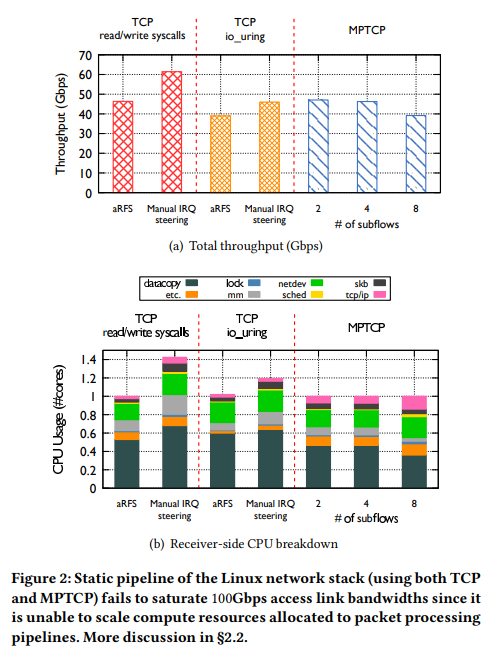
Figure 2(a)는 단순 하나의 TCP socket을 사용해 read/write하는 응용이 100Gbps를 달성할 수 없음을 보였다. 심지어는 다양한 오프로딩 기술과 Jumbo frame, TSO, GRO, aRFS의 aggregation기법 (Table 1), 그리고 새로운 인터페이스인 io_uring과 MPTCP을 사용했음에도 불구하고 말이다. Jumbo frame과 TSO/GRO는 더 많은 양의 payload를 packet buffer (or skbs)에다가 담음으로써 packet당 프로세싱 오버헤드를 줄여준다. aRFS는 NIC으로 하여금, 수신된 프레임이 애플리케이션이 구동 중인 CPU에 가도록 하는 기법이다. 이와 함께, DCA는 수신된 프레임을 곧바로 동일한 CPU의 L3 cache로 보냄으로써 성능을 극대화할 수 있다.
Figure 2(b)는 CPU 프로파일링 결과이다. 분석 결과에 따르면, DCA를 활성화하였더라도, CPU의 병목은 수신 측의 kernel에서 userspace로 data copy를 하는 곳에 있음을 확인할 수 있었다. Data copy는 recv() system call때 수행된다. 추가로, aRFS를 활성화했을 때, 인터럽트 (IRQs)는 애플리케이션이 실행 중인 CPU core로 조절이 됐고, 그에 따라 TCP/IP, netdev 등의 네트워크 계층의 처리도 동일한 CPU core에서 처리됐다.
(신기한 점은,) aRFS를 비활성화 하고 수동으로 인터럽트를 동일한 NUMA 노드이지만 애플리케이션과 다른 CPU core에 지정하였더니 성능이 조금 더 상승하였다 (약 ~60 Gbps, Figure 2(a)의 두 번째 줄). 이는 TCP/IP, netdev 등의 처리가 다른 CPU core에 오프로딩 된 것이라고 볼 수 있고, 그에 따라 애플리케이션 CPU core가 data copy에 더 많은 CPU를 사용할 수 있게 되었기 때문이다.
심지어 리눅스 최신 io_uring 기능 및 aRFS 활성화 (Figure 2(a) 세 번째)와 수동으로 NUMA-local IRQ steering (Figure 2(a) 네 번째) 환경에서는, io_uring이 성능이 그다지 개선되지 않는 것을 확인하였다. 이 상태에서도 여전히 data copy가 지배적인 overhead를 차지하고 있었다. 실제로 기존 TCP보다 약간의 성능 하락이 있었는데, 이는 io_uring이 socket receive call을 분리된 커널 스레드에 dispatch함에 따라 애플리케이션 스레드와 lock 경합이 발생하였기 때문이었다 ( io_uring의 구조를 정확히 잘 모르기 때문에 약간 잘 이해되지 않는다.).
MPTCP를 사용하는 환경 하에서는 aRFS를 사용하는 것이 최고의 성능을 보여주었다. Subflow의 개수와 상관없이 모든 packet 처리는 애플리케이션이 실행 중인 CPU core와 동일한 곳에서 진행됐다. Subflow의 개수가 늘어날수록 성능이 감소했으며, 이는 네트워크 계층의 처리 부하가 증가함에서 기인한다. aRFS 없이는 subflow의 인터럽트가 무작위 CPU core에 배분되고, 이는 다른 NUMA에 배분되어 오히려 성능을 낮출 가능성이 있다 (MPTCP의 subflow interrupt를 수동으로 지정하는 것은 불가능했다고 한다).
요약하여, 현 네트워크 스택의 packet 처리 파이프라인은 정적 (data copy와 네트워크 처리 계층이 동일 코어에 묶여있음)이다. 그 결과로 packet을 처리하는 데 필요한 자원을 동적으로 늘리거나 줄일 수 없다. 심지어는 남아도는 CPU core가 있는데도, fully utilization을 할 수 없는 것이다. Data copy를 제거한다고 할지라도 (Tx: MSG_ZEROCOPY, Rx: mmap), 단순한 계산을 통해서 네트워크 스택은 떠오르는 수백 Gbps를 1 코어를 통해 여전히 달성할 수 없다는 것을 확인할 수 있다. packet 처리 파이프라인이 여전히 코어 하나에 묶여 있기 때문. 따라서 multi-core 처리는 필수불가결하다.
(2) Static and dedicated pipeline: short message processing에 대한 scalability 부족

서버에게 4KB의 RPC 요청을 보내는 애플리케이션을 실험했을 때, 단일 소켓이 대략 9.88 Gbps까지 달성할 수 있음을 확인하였다. 해당 문제는 Tx-side에서 병목이 발생했었다. Tx-side의 CPU 사용량을 분석한 Figure 3이 보여주듯, TCP/IP 처리와 netdevice subsystem 처리 과정이 전체 CPU 사용량 중에서 절반 가까이를 차지하는 큰 오버헤드임을 확인할 수 있었다. 언급했듯, 현 네트워크 스택의 단일 CPU core에 제한된 처리 과정은 동적으로 CPU 사용량을 늘리거나 줄이기 어렵게 만들었다.
다른 인터페이스인 io_uring을 사용하는 동일한 실험을 진행했지만, 여전히 성능에 향상은 얻을 수 없었다. MPTCP는 이 시나리오에서 도움이 되지 않는다. 그 이유로는 (1) Tx-side의 네트워크 계층 처리는 애플리케이션 코어에서 진행되기 때문에 (Tx-side이므로) multiple subflow를 싱글 코어에서 돌리는 것은 도움이 되지 않기 때문이고, (2) MPTCP는 CPU 부하에 따라 런타임에 subflow의 개수를 동적으로 조절할 수 없기 때문이다.
애플리케이션이 네트워크 계층 처리의 병목 문제를 각기 다른 스레드에 소켓을 열고 여러 소켓을 이용해 데이터를 보내는 방식으로 해결할 수는 있겠지만, 개발자가 얼마나 많은 소켓이 필요할지 (특히 가상화 환경이나 멀티테넌트 환경에서) 추측하기는 매우 어려운 과정이다. 게다가 애플리케이션 및 애플리케이션에 링크 된 userspace 라이브러리는 네트워크의 congestion 상황과 CPU 사용량에 대한 정보에 한계가 있어서, 애플리케이션이 packet을 여러 소켓에 어떻게 스케쥴링 할 지도 한계가 있다. 가장 이상적인 방법은 네트워크 스택이 알아서 동적이고 투명하게 (애플리케이션이 모르게) 놀고 있는 CPU에다가 새로운 연결을 수립해서 throughput을 올리는 방법일 것이다. 그리고 이러한 동적인 연결 확장은 CPU에 의해서 throughput 성능에 한계가 도달할 때만 조절되도록 함으로써, TCP의 congestion control 같은 protocol 정책도 유지되도록 할 수 있을 것이다.
(3) Tightly-integrated pipeline: performance isolation 불가
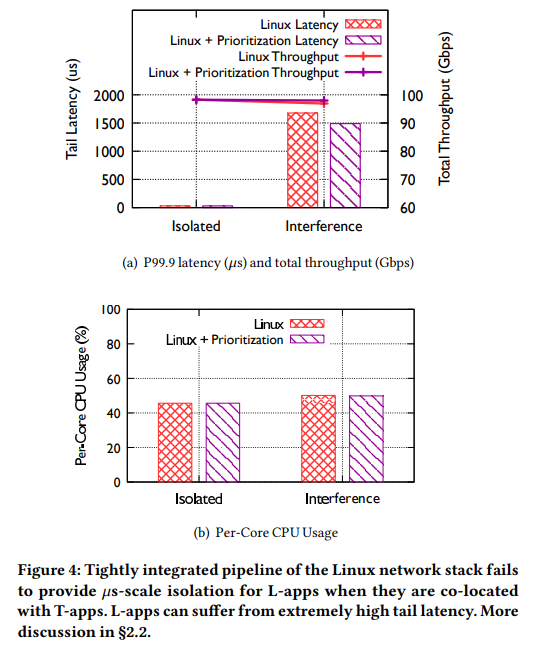
L-apps와 T-apps가 공존할 때의 성능 간섭을 이해하기 위해서, 1개의 L-app과 8개의 T-app을 동일한 NUMA (CPU 개수보다 애플리케이션 개수가 더 많은 상황)위에서 돌려보았다. 애플리케이션마다 특정 CPU core에 피닝 (고정)하지는 않았고, 그러므로 CPU 스케쥴러가 애플리케이션을 동일 NUMA 내의 CPU를 자유자재로 왔다갔다 할 수 있도록 하였다. aRFS를 포함한 모든 최적화를 활성화하였다.
Figure 4 (a)는 애플리케이션이 격리되었을 때(Isolated)와 그렇지 않았을 때(Interference)의 L-app의 tail latency와 전체 throughput 결과를 보여준다. 간섭 상황에서는 격리 환경보다 L-app이 37배가 증가된 tail latency를 보여주었다. 이 극단적인 증가는 네트워크 계층의 처리와 애플리케이션 코어가 강하게 통합되어 있기 때문이다. 현 상황에서는 코어보다 애플리케이션의 개수가 더 많은 상황이므로, 특정 시점에서 L-apps가 T-apps과 CPU 코어를 공유하는 것은 불가피하다. 결국 이 상황이 발생하면, 커널은 동일한 CPU 위에 있는 두 애플리케이션에 대한 네트워크 계층 처리를 진행할 것이고 결국 간섭이 발생한다. 이 간섭 상황에서는 T-app의 네트워크 처리로 인해 L-app의 네트워크 처리 과정이 잠시 중단될 수 있고, 결국 이 것이 tail latency를 상당하게 증가시키는 것이다.
L-app의 트래픽에 대한 우선순위를 높이는 방법도 해결책이 되지는 못한다. 우선순위 구분은 두 개의 계층에서 이루어진다. (1) L-app packet을 전송할 때 qdisc 계층에서 pfifo_fast 스케쥴링 정책을 사용함으로써 우선 처리되는 방법, (2) L-app의 프로세스에 대한 nice value를 -20으로 설정함으로써 CPU 스케쥴러에 의한 우선순위를 높이는 방법 (Tx와 Rx-side 모두)이 있다. 하지만 이 두 가지 방법을 모두 적용했음에도, Figure 4 (a)의 Linux+Prioritization의 결과는 성능 향상을 얻지 못했음을 보여주었다. (1) qdisc 방식은 처음부터 qdisc 계층에 대기중인 내용이 많지 않아 효과가 크지 않았다. 이는 TCP Small Queue (TSQ)의 특징 때문으로, 이는 bufferbloat을 최소화하기 위해서 qdisc 계층에 in-flight 상태에 있는 packet byte를 제한한다. (2) CPU 스케쥴링 우선순위 방식은 다음과 같은 두 가지 이유로 효과가 없었다. 1) 수신 측의 네트워크 계층 처리 작업은 대부분 IRQ thread (Rx: 수신 packet 처리, Tx: TSQ 처리)에서 발생한다. 따라서 애플리케이션 thread의 우선순위를 높이는 것은 그닥 효과가 없는 것이다. 2) IRQ 처리 우선순위를 높이는 방식이 있더라도, IRQ 처리는 태생이 non-preemptive이므로 완전한 해결책일 수 없다. 따라서 L-apps는 T-apps에 의해 여전히 블록될 수 있다.
우선순위 기법도 효과가 딱히 없었다. 따라서 performance isolation을 달성하기 위한 유일한 방법은 L-apps와 T-apps를 처리하기 위한 네트워크 계층 자체를 분리하는 것이다. 하지만 애플리케이션 코어와 강하게 결합되어 있는 packet 처리 파이프라인 때문에, 그렇게 하는 것은 불가능하다.
3. NetChannel 디자인
언급된 문제를 해결하기 위해서 NetChannel은 네트워크 스택을 다음과 같이 3개의 레이어로 나누어 파이프라인을 disaggregate하였다: (1) Virtual Network System (VNS) layer, (2) NetDriver layer, and (3) NetScheduler layer.
VNS 계층은 애플리케이션에게 인터페이스 (e.g., socket, RPC)를 인터페이스 시맨틱을 유지하면서 제공한다. 이 인터페이스들은 "virtual"인데, 그 이유는 현 네트워크 스택과는 다르게 오로지 애플리케이션 데이터를 버퍼 해두기만 하며 다른 packet 처리 파이프라인과는 분리되어 있기 때문. 그 밑에는 NetDriver 계층이 multi-queue 장치를 generic channel abstraction을 통해 추상화하여 상위 계층 (VNS)에게 제공한다. VNS의 애플리케이션 인터페이스와 NetDriver 계층의 channels 추상화를 분리함으로써 더 유연하고 잘게 쪼개진 단위에서의 multiplexing/demultiplexing 및 데이터 스케쥴링이 가능해졌다. 이 multiplexing과 demultiplexing은 NetScheduler 계층에 의해서 제어된다. 이 계층은 pluggable하기 때문에 원하는 목적에 따라서 자유롭게 디자인하고 동적으로 처리 과정에 드는 자원(e.g., CPU core)를 자유자재로 늘리거나 줄일 수 있다.
3.1. VNS Layer
VNS 계층은 인터페이스의 시맨틱을 유지하면서 애플리케이션 인터페이스를 제공한다. 애플리케이션의 수정이 필요없도록 만들기 위해서 NetChannel은 표준 POSIX socket interface를 virtual socket을 통해 제공한다. 애플리케이션 관점에서 이러한 virtual sockets은 일반적인 socket들과 완전히 동일한 시맨틱 (reliable in-order delivery)을 가진다. 늘 그렇듯, 애플리케이션은 이러한 소켓과 표준 system call (e.g., connect, send, recv, epoll)을 통해서 / 혹은 io_uring을 통해서 상호작용할 수 있다.
Ensuring correctness of interface semantics. 각 virtual socket은 내부적으로 Tx와 Rx buffer 쌍을 관리한다. 애플리케이션이 데이터를 virtual socekt으로부터 받거나 혹은 보낼 때, 데이터는 userspace과 virtual socket의 Tx buffer 또는 Rx buffer에서 복사가 이뤄진다. Virtual socket의 Tx buffer에 있는 데이터는 전송을 위해서 NetDriver layer로 전달된다. NetDriver로부터 전달받은 data는 virtual socket의 Rx buffer에 들어간다. 하위 레이어 (channels)에서 네트워크 프로토콜을 통해 신뢰성 있는 전송을 보장받을 수는 있지만, VNS는 virtual socket 내에서 in-order 전송을 보장하기 위해서 book-keeping 기법을 필요로 한다. 이는 이 하나의 virtual socket이 NetDriver layer의 여러 channel과 상호작용할 수도 있기 때문. 결국 packet이 out-of-order로 도착할 여지가 있고, 이를 해결하기 위해서 VNS에서는 추가로 sequence number를 구현하였다 (VNS와 NetDriver 사이에서만 사용할 것으로 예상된다).
Decoupling data copy from application threads. 또한 VNS는 userspace와 kernel 사이의 data copy를 위해서 CPU core별로 worker thread를 관리한다. Virtual socket에서의 데이터 복사 작업은 작은 단위로 잘게 쪼개질 수 있으며, 여러 worker threads로 분리될 수 있다 (즉, 여러 코어에서 복사를 동시에 처리할 수 있다). 이는 throughput-bound 애플리케이션에서의 데이터 복사 작업을 자유자재로 늘림으로써 여러 코어를 사용할 수 있게 한다.
3.2. NetDriver 계층
NetDriver 계층은 network와 원격 서버를 multi-queue 장치로서 추상화하고, 이 큐와 유사한 channels 이라는 것을 노출한다. 3.2에서는 (1) channel의 추상화, (2) 네트워크 계층의 프로세싱을 소켓으로부터 분리하는 NetDriver의 메커니즘, (3) 새로운 네트워크 전송 계층 디자인을 쉽게 통합시킬 수 있는 NetDriver의 메커니즘, 그리고 (4) 그 외 buffer overflow 관리나 HOL (head-of-line) blocking을 피하는 방법 등에 대해서 다룬다.
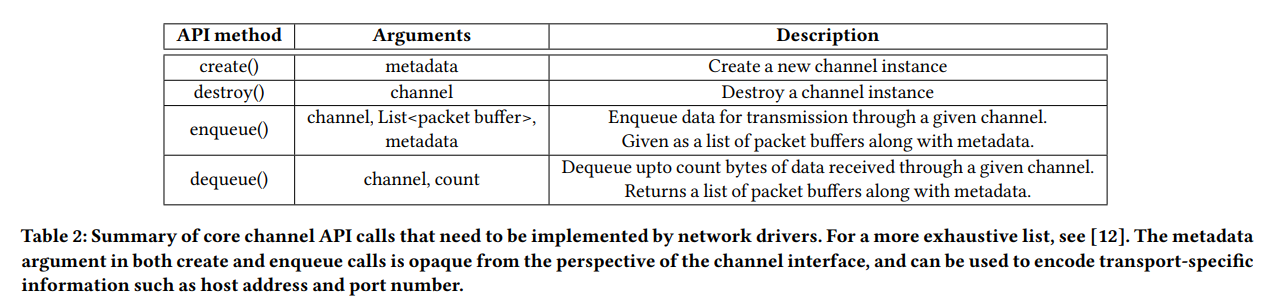
Channel 추상화. NetDriver에서 각 channel은 Tx/Rx 큐의 쌍, 그리고 독립적인 네트워크 계층 처리 파이프라인 인스턴스로 구성되어 있다. 이 인스턴스 하나는 하나의 L4 연결을 구현한다. Channel을 사용하기 위한 API (Table 2)는 단순하고 범용적이어서 다양한 전송 계층 프로토콜을 포함시킬 수 있도록 한다. 특히, 이는 connection-oriented stream-based 전송 계층 (e.g., TCP, DCTCP), connection-less message-oriented 전송 계층 (e.g., pHost, Homa, dcPIM) 등을 지원한다. 예를 들어, 전자의 경우(연결/스트림 기반)에는 channel API의 create call을 이용해 connection이 생성된다. 그 다음으로 stream에 있는 임의의 데이터 청크가 channel의 enqueue call을 이용해 전달된다. 후자의 경우 (비연결성, 메시지 기반)에는 channel의 creation 과정에서 연결이 수립되지 않으며, 각각 개별적인 메시지가 channel의 enqueue call을 통해서 (목적지 정보와 함께) 전달된다. (사실 이 추상화는 socket API와 어떠한 차이를 지니는지 아직 와닿지는 않는다. TCP, UDP 모두 socket API와 system call인 send/recv 로 구현이 가능한 것 처럼...)
Decoupled network layer processing. NetDriver의 channel은 VNS layer의 virtual interface와 분리되어 있다. 이러한 구조는 각 소켓과 애플리케이션이 사용중인 CPU core들로부터 network layer processing을 분리할 수 있다. 따라서 NetDriver는 서버에서 실행준인 애플리케이션의 수와 상관없이, 그리고 애플리케이션이 사용중인 소켓 및 CPu core 수에 상관없이 주어진 서버 사이에서 하나 혹은 그 이상의 channels을 생성할 수 있다. 나아가, 이는 channel과 VNS layer의 virtual interface 사이에서 데이터를 작은 단위로 demultiplexing/multiplexing 하면서 교환할 수 있도록 한다. 이는 재밌는 활용 방안을 제공하는데, 예를 들어 하나의 channel이 CPU 사용량이 높은 경우 다음으로 처리해야 할 virtual socket 내의 데이터는 동적으로 다른 channel에 스케쥴링 될 수 있도록 할 수 있다. 이러한 동적인 multiplexing 기법은 네트워크 스택 처리에 있어서 여러 CPU core들을 사용할 수 있도록 한다.
Integration new transport design. NetDriver는 multi-queue 장비의 추상화로서, 새로운 전송 계층을 통합시키는 것은 새로운 디바이스 드라이버를 작성하는 것과 동일하다. 이는 새로운 프로토콜을 통합하고 실험하는 것을 쉽게 만든다. 프로토콜 개발자는 socket interface와 관련된 무거운 API들 (e.g., epoll)을 구현할 필요가 없으며, 오로지 Table 2에 주어진 channel API만 고려하면서 개발하면 될 것이다.
Piggybacking on transport-level flow control. (Piggybacking [링크]이 분리된 ACK 말고 data에 ack를 올려서 보내는 기법을 의미하는 것도 있는 듯한데, 여기는 편승한다 라는 의미로 쓰인 것 같다...) Virtual socket의 Rx 버퍼 오버플로우를 피하기 위해서, NetDriver는 backpressure 방식을 이용함으로써, 별도의 새로운 flow control을 도입할 필요 없이 전송 계층의 flow control을 유도한다 (즉, 전송 계층이 구현한 flow control에 편승한다). 만약 virtual socket의 Rx buffer가 가득 차면, VNS는 channels로부터 data를 읽어들이는 것을 중단한다. 이는 다시 channel의 Rx buffer에 data가 쌓이게 되며, 결국에는 전송계층의 flow control을 유발한다. VNS는 virtual socket의 Rx buffer가 다시 사용 가능해지면 (가득 참이 해소되면) 데이터 수신을 재개한다.
Alleviating HoL Blocking. 단 하나의 channel이 여러개의 virtual socekt에 의해 공유될 가능성이 있음에 따라, 하나의 virtual socket이 HoL blocking을 유발하는 케이스를 고려해야 할 필요성이 생겼다. 이는 만약 애플리케이션이 virtual socket으로부터 특정 이유 (오작동 혹은 다른 작업 처리)로 데이터를 읽어가지 않는 경우에 발생할 수 있다. 이는 Rx buffer가 점점 참에 따라 다른 virtual socket들로 하여금 해당 channel을 사용할 수 있는 기회를 잃게 하므로 문제가 된다. (NetScheduler가 새로운 channel을 할당해서 해결을 시도하겠지만, 비효율적이다.)
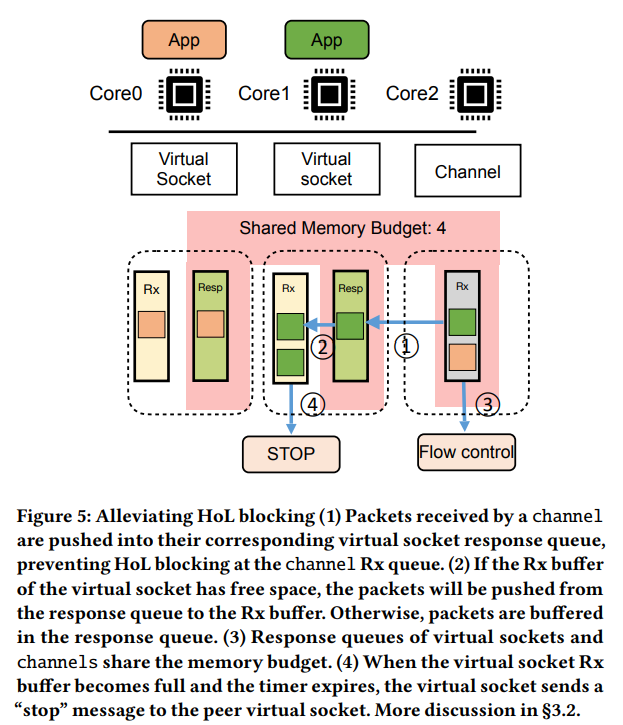
이 문제를 처리하기 위해서 NetChannel은 Figure 5처럼 응답 queue를 virtual socket별로 유지를한다. 아이디어는 Rx buffer가 가득찬 virtual socket의 Rx buffer는 unblocking 상태로 두되 전송만 중단하는 것이다. 이 응답 queue는 링크드 리스트 관리로 인한 약간의 메모리 오버헤드를 유발한다. ① Channel의 Rx buffer로 packet의 도착할 때 마다 해당 packet은 적절한 virtual socket의 응답 eueue로 곧바로 전달된다. 따라서 Channel의 Rx buffer가 가득 차는 일이 해소되는 것이다. 다음, ② 그 packet은 응답 queue에서 virtual socket의 Rx buffer로 전달한다. ③ 각 virtual socket의 응답 queue를 channel buffer의 메모리 예산과 공유함으로써, response queue의 상황도 고려해 flow control이 트리거 될 수 있도록 하였다. ④ 만약 virtual socekt의 Rx buffer가 가득 차게된다면, worker 스레드는 timer를 설정한 뒤, 더이상 데이터를 보내지 못하도록 control message 'stop'을 상대방의 virtual socket으로 보낸다. virtual socket이 stop message에 대한 ACK를 수신하면, respones queue에 있던 모든 packet들을 virtual socket의 Rx buffer로 전달하여 channel의 buffer에 공간이 생기도록 만든다. Virtual socket의 Rx buffer가 여유로워진다면 다시 'resume' 메시지를 상대방에게 전달한다. (이해한 내용을 요약하자면, 하나의 channel Rx buffer를 통해서 packet을 demultiplexing하는 경우에는 각각의 virtual socket들이 독립적으로 운용되지 못하고 간섭을 받기 쉽다. 상황이 악화되면 HoL이 발생할 수 있고. 따라서 각각 virtual socket에 배분을 먼저 시켜놓고, 그 다음에 버퍼의 상황을 고려하도록 구현한 것으로 보인다.)
3.3 NetScheduler Layer
NetScheduler는 3개의 역할을 수행한다: (1) 작은 단위 (fine-grained)의 multiplexing 및 애플리케이션 데이터들을 channel에 스케쥴링 하는 일, (2) 호스트들 사이에서 channel의 개수를 동적으로 늘리고 줄이는 일, (3) data copy 요청을 per-core data copy worker thread에게 스케쥴링 하는 일. 이 논문에서 다루는 scheduler는 최적의 schduler를 제안하는 것이 아니라 하나의 방법임을 안내한다. 누구든 입맛에 맞는 새로운 scheduling 정책을 이 NetScheduler Framework 내에서 구현할 수 있다.
Dynamic scheduling of application data to channels. 어떠한 상황에서든 하나 혹은 그 이상의 channel들이 호스트 사이에서 존재할 것이다. 애플리케이션으로부터 데이터를 받았다면 (Tx), NetScheduler는 (설정할 수 있는) scheduling 정책을 이용해 skb 단위로 어느 channel로 data를 보낼지 결정한다. 이를 통해서 channel들 사위에서 섬세하게 (fine-grained) 로드밸런싱을 달성할 수 있다.
Dynamic scaling and placement of channels. NetScheduler는 큰 단위의 시간 규모로 scheduling metric을 모니터링해서 호스트 사이의 channel 개수를 늘리거나 줄일 수 있다. 예를 들어, channel worker들의 CPU 평균 사용량이 꾸준하게 높다면 channel의 수를 늘리는 정책을 펼칠 수 있다. 나아가서 NetScheduler는 channel들을 어느 core에서 실행할 건지 제어할 수 있다. 이를 통해서 L-app과 T-app을 담당하는 channel들의 실행 core를 분리하여 performance isolation을 달성할 수 있다.
Dynamic scheduling of data copy requests. NetScheduler는 여러 CPU core에서 실행되는 virtual socket들에 의해 생성된 data copy 요청을 스케쥴링 한다. 이는 cross-NUMA data copy 오버헤드를 피하기 위해서 애플리케이션이 실행되는 core와 동일한 NUMA node에서 처리하도록 한다. 이 방법을 통해 T-apps의 data copy를 여러 core에 분산하여 병렬화를 달성할 수 있음을 section 5에서 보였다.



