
- Today
- Total
Byeo
Listen socket의 TCP SYN 처리 2 본문
지금까지 tcp_conn_request() 함수의 6867줄까지 확인을 했습니다.
남은 6869줄부터 어떤 기능이 있을지 확인해봅니다.
현재까지의 흐름도입니다:

5. tcp_conn_request
5-7. timestamp
// net/ipv4/tcp_input.c/tcp_conn_request() :6869
if (tmp_opt.tstamp_ok)
tcp_rsk(req)->ts_off = af_ops->init_ts_off(net, skb);
af_ops는 tcp_request_sock_ipv4이고, init_ts_off 함수는 tcp_v4_init_ts_off입니다.
// net/ipv4/tcp_ipv4.c/tcp_v4_init_ts_off() :102
static u32 tcp_v4_init_ts_off(const struct net *net, const struct sk_buff *skb)
{
return secure_tcp_ts_off(net, ip_hdr(skb)->daddr, ip_hdr(skb)->saddr);
}
secure_tcp_ts_off는 다음과 같이 정의되어 있습니다.
// net/core/secure_seq.c/secure_tcp_ts_off() :117
u32 secure_tcp_ts_off(const struct net *net, __be32 saddr, __be32 daddr)
{
if (net->ipv4.sysctl_tcp_timestamps != 1)
return 0;
ts_secret_init();
return siphash_2u32((__force u32)saddr, (__force u32)daddr,
&ts_secret);
}
SYN packet에 timestamp가 있는 경우, 해쉬 함수를 통해서 임의의 값을 얻어와 tcp_rsk(req)->ts_off에 값을 넣어줍니다.
5-8. init_seq
want_cookie는 false였고, isn도 출력 시 0으로 출력됩니다. 따라서 아래의 함수를 실행합니다.
// net/ipv4/tcp_input.c/tcp_conn_request() :6872
if (!want_cookie && !isn) {
/* Kill the following clause, if you dislike this way. */
if (!net->ipv4.sysctl_tcp_syncookies &&
(net->ipv4.sysctl_max_syn_backlog - inet_csk_reqsk_queue_len(sk) <
(net->ipv4.sysctl_max_syn_backlog >> 2)) &&
!tcp_peer_is_proven(req, dst)) {
/* Without syncookies last quarter of
* backlog is filled with destinations,
* proven to be alive.
* It means that we continue to communicate
* to destinations, already remembered
* to the moment of synflood.
*/
pr_drop_req(req, ntohs(tcp_hdr(skb)->source),
rsk_ops->family);
goto drop_and_release;
}
isn = af_ops->init_seq(skb);
}
tcp_syncookies가 0이라고 가정하고 진행해보겠습니다. 조건문에서는 tcp_syncookies 값을 체크하고, 현재 icsk_accept_queue의 길이가 sysctl에 지정된 max_syn_backlog의 75%를 넘지 않았는지 확인합니다. 그리고 함수명으로 추측컨대 검증된 대상이 아니라면 drop_and_release를 실행합니다.
만약 위 조건에 해당하지 않는다면 init_seq함수를 통해서 seqeunce number를 초기화 합니다.
마찬가지로 init_seq는 tcp_request_sock_ipv4_ops에 정의되어 있고, 다음과 같이 생겼습니다.
// net/ipv4/tcp_ipv4.c/tcp_v4_init_seq() :94
static u32 tcp_v4_init_seq(const struct sk_buff *skb)
{
return secure_tcp_seq(ip_hdr(skb)->daddr,
ip_hdr(skb)->saddr,
tcp_hdr(skb)->dest,
tcp_hdr(skb)->source);
}
그리고 secure_tcp_seq는 다음과 같이 정의되어 있습니다.
// net/core/secure_seq.c/secure_tcp_seq() :132
/* secure_tcp_seq_and_tsoff(a, b, 0, d) == secure_ipv4_port_ephemeral(a, b, d),
* but fortunately, `sport' cannot be 0 in any circumstances. If this changes,
* it would be easy enough to have the former function use siphash_4u32, passing
* the arguments as separate u32.
*/
u32 secure_tcp_seq(__be32 saddr, __be32 daddr,
__be16 sport, __be16 dport)
{
u32 hash;
net_secret_init();
hash = siphash_3u32((__force u32)saddr, (__force u32)daddr,
(__force u32)sport << 16 | (__force u32)dport,
&net_secret);
return seq_scale(hash);
}
즉, sequence number 초기화는 임의의 해쉬를 통해서 이뤄집니다. 해쉬 값으로는 source ip, dest ip, source port, dest port가 들어갑니다.
5-9. tcp_ecn_creqte_request
다음으로 실행하는 함수는 tcp_ecn_creqte_request입니다.
// net/ipv4/tcp_input.c/tcp_conn_request() :6893
tcp_ecn_create_request(req, skb, sk, dst);
ecn은 explicit congestion notification의 약자로, DCTCP 등의 프로토콜에서 사용합니다. 일반적인 TCP의 경우에는 사용할 일이 없어서 이를 검증하는 역할을 수행합니다. 만약 ECN을 사용해야하는 congestion control algorithm인 경우, reqsk의 ecn_ok를 1로 set합니다.
// net/ipv4/tcp_input.c/tcp_ecn_create_request() :6640
/* RFC3168 : 6.1.1 SYN packets must not have ECT/ECN bits set
*
* If we receive a SYN packet with these bits set, it means a
* network is playing bad games with TOS bits. In order to
* avoid possible false congestion notifications, we disable
* TCP ECN negotiation.
*
* Exception: tcp_ca wants ECN. This is required for DCTCP
* congestion control: Linux DCTCP asserts ECT on all packets,
* including SYN, which is most optimal solution; however,
* others, such as FreeBSD do not.
*
* Exception: At least one of the reserved bits of the TCP header (th->res1) is
* set, indicating the use of a future TCP extension (such as AccECN). See
* RFC8311 §4.3 which updates RFC3168 to allow the development of such
* extensions.
*/
static void tcp_ecn_create_request(struct request_sock *req,
const struct sk_buff *skb,
const struct sock *listen_sk,
const struct dst_entry *dst)
{
const struct tcphdr *th = tcp_hdr(skb);
const struct net *net = sock_net(listen_sk);
bool th_ecn = th->ece && th->cwr;
bool ect, ecn_ok;
u32 ecn_ok_dst;
if (!th_ecn)
return;
ect = !INET_ECN_is_not_ect(TCP_SKB_CB(skb)->ip_dsfield);
ecn_ok_dst = dst_feature(dst, DST_FEATURE_ECN_MASK);
ecn_ok = net->ipv4.sysctl_tcp_ecn || ecn_ok_dst;
if (((!ect || th->res1) && ecn_ok) || tcp_ca_needs_ecn(listen_sk) ||
(ecn_ok_dst & DST_FEATURE_ECN_CA) ||
tcp_bpf_ca_needs_ecn((struct sock *)req))
inet_rsk(req)->ecn_ok = 1;
}
5-10. 값 초기화
// net/ipv4/tcp_nput.c/tcp_conn_request() :6901
tcp_rsk(req)->snt_isn = isn;
tcp_rsk(req)->txhash = net_tx_rndhash();
tcp_rsk(req)->syn_tos = TCP_SKB_CB(skb)->ip_dsfield;
이제 몇몇 req field들을 채워줍니다.
- snt_isn은 위에서 init_seq를 통해서 초기화했던 sequence number를 지정합니다.
- txhash는 임의의 랜덤 값을 지정합니다.
- syn_tos는 tcp skb에 있던 ip_dsfield를 가져옵니다. (IPv4 tos field)
5-11. tcp_openreq_init_rwin
// net/ipv4/tcp_input.c/tcp_conn_request() :6904
tcp_openreq_init_rwin(req, sk, dst);
tcp_openreq_init_rwin은 receive window size와 관련된 함수로, flow control을 위해 초기화 하는 함수입니다.
// net/ipv4/tcp_minisocks.c/tcp_openreq_init_rwin() :360
/* Warning : This function is called without sk_listener being locked.
* Be sure to read socket fields once, as their value could change under us.
*/
void tcp_openreq_init_rwin(struct request_sock *req,
const struct sock *sk_listener,
const struct dst_entry *dst)
{
struct inet_request_sock *ireq = inet_rsk(req);
const struct tcp_sock *tp = tcp_sk(sk_listener);
int full_space = tcp_full_space(sk_listener);
u32 window_clamp;
__u8 rcv_wscale;
u32 rcv_wnd;
int mss;
mss = tcp_mss_clamp(tp, dst_metric_advmss(dst));
window_clamp = READ_ONCE(tp->window_clamp);
/* Set this up on the first call only */
req->rsk_window_clamp = window_clamp ? : dst_metric(dst, RTAX_WINDOW);
/* limit the window selection if the user enforce a smaller rx buffer */
if (sk_listener->sk_userlocks & SOCK_RCVBUF_LOCK &&
(req->rsk_window_clamp > full_space || req->rsk_window_clamp == 0))
req->rsk_window_clamp = full_space;
rcv_wnd = tcp_rwnd_init_bpf((struct sock *)req);
if (rcv_wnd == 0)
rcv_wnd = dst_metric(dst, RTAX_INITRWND);
else if (full_space < rcv_wnd * mss)
full_space = rcv_wnd * mss;
/* tcp_full_space because it is guaranteed to be the first packet */
tcp_select_initial_window(sk_listener, full_space,
mss - (ireq->tstamp_ok ? TCPOLEN_TSTAMP_ALIGNED : 0),
&req->rsk_rcv_wnd,
&req->rsk_window_clamp,
ireq->wscale_ok,
&rcv_wscale,
rcv_wnd);
ireq->rcv_wscale = rcv_wscale;
}
EXPORT_SYMBOL(tcp_openreq_init_rwin);
TCP receiver가 sender에게 flow control을 위해서 남은 buffer size를 얼마만큼으로 알려줄 지는 'sysctl net.ipv4.tcp_adv_win_scale'에 의해서 결정됩니다.
5-11-1. tcp_full_space란
// include/net/tcp.h/tcp_win_from_space() :1399
static inline int tcp_win_from_space(const struct sock *sk, int space)
{
int tcp_adv_win_scale = sock_net(sk)->ipv4.sysctl_tcp_adv_win_scale;
return tcp_adv_win_scale <= 0 ?
(space>>(-tcp_adv_win_scale)) :
space - (space>>tcp_adv_win_scale);
}
각 값을 다시 계산하면 다음과 같습니다.
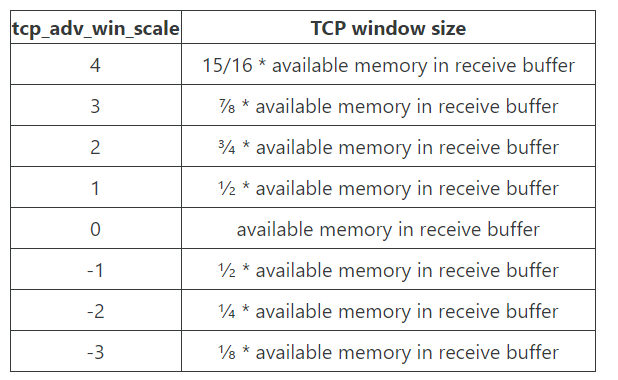
즉, sk->sk_rcvbuf가 현재 131072이고 tcp_adv_win_scale이 1이라면, 65536을 반환합니다. 자세한 설명은 cloudflare의 블로그를 참고하시길 바랍니다. 1
dst_metric으로 시작하는 함수들은 ip route 명령어를 통해서 지정된 값을 읽어오는 함수입니다.
ip route help를 입력하면 다음을 확인할 수 있습니다.

initrwnd NUMBER (Linux 2.6.33+ only) the initial receive window size for connections to this destination. Actual window size is this value multiplied by the MSS of the connection. The default value is zero, meaning to use Slow Start value.
자세한 내용은 ip route manual 사이트를 참고하시길 바랍니다. 2
따라서 tcp_openreq_init_rwin은 mss를 알아내고 적절한 rcv_wscale을 지정합니다.
먼저, RTAX_INITRWND는 사용자가 지정하지 않는 한 0으로 설정됩니다.
tcp_select_initial_window 함수를 호출하기 전에 값들을 출력해보니 다음과 같이 설정되어 있었습니다.

실제로 full_space는 저희가 예상했던대로 sysctl tcp_rmem에서 설정해놓았던 값인 131072의 절반이 되었고, window_clamp와 rcv_wnd는 0을 갖고 있었습니다.
5-11-2. tcp_select_initial_window
// net/ipv4/tcp_ouput.c/tcp_select_initial_window() :208
/* Determine a window scaling and initial window to offer.
* Based on the assumption that the given amount of space
* will be offered. Store the results in the tp structure.
* NOTE: for smooth operation initial space offering should
* be a multiple of mss if possible. We assume here that mss >= 1.
* This MUST be enforced by all callers.
*/
void tcp_select_initial_window(const struct sock *sk, int __space, __u32 mss,
__u32 *rcv_wnd, __u32 *window_clamp,
int wscale_ok, __u8 *rcv_wscale,
__u32 init_rcv_wnd)
{
unsigned int space = (__space < 0 ? 0 : __space);
/* If no clamp set the clamp to the max possible scaled window */
if (*window_clamp == 0)
(*window_clamp) = (U16_MAX << TCP_MAX_WSCALE);
space = min(*window_clamp, space);
/* Quantize space offering to a multiple of mss if possible. */
if (space > mss)
space = rounddown(space, mss);
/* NOTE: offering an initial window larger than 32767
* will break some buggy TCP stacks. If the admin tells us
* it is likely we could be speaking with such a buggy stack
* we will truncate our initial window offering to 32K-1
* unless the remote has sent us a window scaling option,
* which we interpret as a sign the remote TCP is not
* misinterpreting the window field as a signed quantity.
*/
if (sock_net(sk)->ipv4.sysctl_tcp_workaround_signed_windows)
(*rcv_wnd) = min(space, MAX_TCP_WINDOW);
else
(*rcv_wnd) = min_t(u32, space, U16_MAX);
if (init_rcv_wnd)
*rcv_wnd = min(*rcv_wnd, init_rcv_wnd * mss);
*rcv_wscale = 0;
if (wscale_ok) {
/* Set window scaling on max possible window */
space = max_t(u32, space, sock_net(sk)->ipv4.sysctl_tcp_rmem[2]);
space = max_t(u32, space, sysctl_rmem_max);
space = min_t(u32, space, *window_clamp);
*rcv_wscale = clamp_t(int, ilog2(space) - 15,
0, TCP_MAX_WSCALE);
}
/* Set the clamp no higher than max representable value */
(*window_clamp) = min_t(__u32, U16_MAX << (*rcv_wscale), *window_clamp);
}
EXPORT_SYMBOL(tcp_select_initial_window);
앞서 계산한 space, window_clamp, init_rcv_wnd 등의 값에 따라서 rcv_wscale, rcv_wnd, window_clamp 값을 재지정합니다.
코드를 따라가면 계산과정은 그리 어렵지는 않습니다. 마지막으로 tcp_select_initial_window함수가 끝난 뒤, 값이 어떻게 변했는지 출력해보고 넘어가겠습니다.
값이 변할 수 있는 변수는 req->rsk_rcv_wnd, req->rsk_window_clamp, rcv_wscale입니다.

출력 결과, 위와 같이 설정되는 것을 확인할 수 있었습니다.
- rsk_rcv_wnd는 $\lfloor{65536 / 1448} \rfloor * 1448$ 로 계산된 값입니다. (65535는 space에서, 1448은 mss 1460 - timestamp 12 에서 유래)
- window clamp는 63335 (U16_MAX) << 7에서 계산된 값입니다.
- rcv_wscale은 $ \lfloor log_{2} {(6291456)} -15 \rfloor = \lfloor 22.58 - 15 \rfloor = 7$ 에서 계산된 값입니다. 6291456은 min(max(net.ipv4.tcp_rmem[2], net.core.rmem_max), window_clamp) 에서 유래한 값입니다. window_clamp는 0으로 들어온 경우 U16_MAX << TCP_MAX_WSCALE 값을 갖고 있습니다.
5-12. sk_rx_queue_set
// net/ipv4/tcp_input.c/tcp_conn_request() :6905
sk_rx_queue_set(req_to_sk(req), skb);
sk_rx_queue_set은 조건에 따라 sk->sk_rx_queue_mapping을 지정하는 함수입니다. 아직 queue를 어떤 자료구조로 어떻게 관리하는지 파악이 잘 안되긴합니다. 그렇더라도 값을 확인해보고 넘어가겠습니다.
// include/net/sock.h/sk_rx_queue_set() :1886
static inline void sk_rx_queue_set(struct sock *sk, const struct sk_buff *skb)
{
#ifdef CONFIG_SOCK_RX_QUEUE_MAPPING
if (skb_rx_queue_recorded(skb)) {
u16 rx_queue = skb_get_rx_queue(skb);
if (WARN_ON_ONCE(rx_queue == NO_QUEUE_MAPPING))
return;
sk->sk_rx_queue_mapping = rx_queue;
}
#endif
}
skb_rx_queue_recorded와 skb_get_rx_queue는 skb->queue_mapping 변수와 관련되어 처리합니다.
// include/linux/skbuff.h :4444
static inline u16 skb_get_rx_queue(const struct sk_buff *skb)
{
return skb->queue_mapping - 1;
}
static inline bool skb_rx_queue_recorded(const struct sk_buff *skb)
{
return skb->queue_mapping != 0;
}
대략 파악할 수 있는 것은 skb->queue_mapping에 값이 있고, 0이 아니면서 NO_QUEUE_MAPPING (USHRT_MAX)가 아닌 경우에 sk->sk_rx_queue_mapping에 값을 보관한다 정도일 것 같습니다.
한 번 skb에 담긴 queue_mapping 값과 sk->sk_rx_queue_mapping값을 뽑아보겠습니다.

skb->queue_mapping의 값이 0이기 때문에 해당 함수는 돌지 않고, 결국 sk_rx_queue_mapping 값은 USHORT_MAX로 남게됩니다.
5-13. tcp_reqsk_record_syn
// net/ipv4/tcp_input.c/tcp_conn_request() :6906
if (!want_cookie) {
tcp_reqsk_record_syn(sk, req, skb);
fastopen_sk = tcp_try_fastopen(sk, skb, req, &foc, dst);
}
현재 우리는 want_cookie가 false인 흐름을 타고있고, 따라서 tcp_reqsk_record_syn 함수가 실행됩니다.
이 함수는 요약해서, 현재 처리중인 SYN packet을 보관하는 작업을 수행합니다. 함수는 아래와 같이 생겼습니다.
// net/ipv4/tcp_input.c/tcp_reqsk_record_syn() :6743
static void tcp_reqsk_record_syn(const struct sock *sk,
struct request_sock *req,
const struct sk_buff *skb)
{
if (tcp_sk(sk)->save_syn) {
u32 len = skb_network_header_len(skb) + tcp_hdrlen(skb);
struct saved_syn *saved_syn;
u32 mac_hdrlen;
void *base;
if (tcp_sk(sk)->save_syn == 2) { /* Save full header. */
base = skb_mac_header(skb);
mac_hdrlen = skb_mac_header_len(skb);
len += mac_hdrlen;
} else {
base = skb_network_header(skb);
mac_hdrlen = 0;
}
saved_syn = kmalloc(struct_size(saved_syn, data, len),
GFP_ATOMIC);
if (saved_syn) {
saved_syn->mac_hdrlen = mac_hdrlen;
saved_syn->network_hdrlen = skb_network_header_len(skb);
saved_syn->tcp_hdrlen = tcp_hdrlen(skb);
memcpy(saved_syn->data, base, len);
req->saved_syn = saved_syn;
}
}
}
다만, 현재 출력값으로서 tcp_sk->saved_syn이 0이기때문에 이 함수의 대부분은 실행되지 않습니다. 하지만 대략 알 수 있듯, saved_syn이 2라면 ethernet header를 포함하여 저장하고, 그렇지 않으면 ip header부터 데이터를 저장하는 그런 구조를 갖고있다는 것을 파악할 수 있습니다.
5-14. tcp_try_fastopen
그 다음으로 호출되는 함수는 tcp_try_fastopen입니다. 양이 조금 되지만 우리는 tcp fastopen을 가정하고 있지 않습니다. tcp_fastopen이 sysctl로 꺼져있다고 가정하고 있기 때문에 곧바로 364번 줄에서 if에 걸려 return NULL을 하게 됩니다.
// net/ipv4/tcp_fastopen.c/tcp_try_fastopen() :350
/* Returns true if we should perform Fast Open on the SYN. The cookie (foc)
* may be updated and return the client in the SYN-ACK later. E.g., Fast Open
* cookie request (foc->len == 0).
*/
struct sock *tcp_try_fastopen(struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
struct tcp_fastopen_cookie *foc,
const struct dst_entry *dst)
{
bool syn_data = TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq + 1;
int tcp_fastopen = sock_net(sk)->ipv4.sysctl_tcp_fastopen;
struct tcp_fastopen_cookie valid_foc = { .len = -1 };
struct sock *child;
int ret = 0;
if (foc->len == 0) /* Client requests a cookie */
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPFASTOPENCOOKIEREQD);
if (!((tcp_fastopen & TFO_SERVER_ENABLE) &&
(syn_data || foc->len >= 0) &&
tcp_fastopen_queue_check(sk))) {
foc->len = -1;
return NULL;
}
if (tcp_fastopen_no_cookie(sk, dst, TFO_SERVER_COOKIE_NOT_REQD))
goto fastopen;
if (foc->len == 0) {
/* Client requests a cookie. */
tcp_fastopen_cookie_gen(sk, req, skb, &valid_foc);
} else if (foc->len > 0) {
ret = tcp_fastopen_cookie_gen_check(sk, req, skb, foc,
&valid_foc);
if (!ret) {
NET_INC_STATS(sock_net(sk),
LINUX_MIB_TCPFASTOPENPASSIVEFAIL);
} else {
/* Cookie is valid. Create a (full) child socket to
* accept the data in SYN before returning a SYN-ACK to
* ack the data. If we fail to create the socket, fall
* back and ack the ISN only but includes the same
* cookie.
*
* Note: Data-less SYN with valid cookie is allowed to
* send data in SYN_RECV state.
*/
fastopen:
child = tcp_fastopen_create_child(sk, skb, req);
if (child) {
if (ret == 2) {
valid_foc.exp = foc->exp;
*foc = valid_foc;
NET_INC_STATS(sock_net(sk),
LINUX_MIB_TCPFASTOPENPASSIVEALTKEY);
} else {
foc->len = -1;
}
NET_INC_STATS(sock_net(sk),
LINUX_MIB_TCPFASTOPENPASSIVE);
return child;
}
NET_INC_STATS(sock_net(sk),
LINUX_MIB_TCPFASTOPENPASSIVEFAIL);
}
}
valid_foc.exp = foc->exp;
*foc = valid_foc;
return NULL;
}
fastopen은 관심사가 아니므로 건너뛰겠습니다.
따라서 fastopen_sk는 NULL이 됩니다.
5-15. hash add and send_syncack
이제 마지막 부분입니다.
// net/ipv4/tcp_input.c/tcp_conn_request() :6924
tcp_rsk(req)->tfo_listener = false;
if (!want_cookie)
inet_csk_reqsk_queue_hash_add(sk, req,
tcp_timeout_init((struct sock *)req));
af_ops->send_synack(sk, dst, &fl, req, &foc,
!want_cookie ? TCP_SYNACK_NORMAL :
TCP_SYNACK_COOKIE,
skb);
if (want_cookie) {
reqsk_free(req);
return 0;
}
inet_csk_reqsk_queue_hash_add함수를 통해서 그동안 만들어온 reqsk를 sk hash에 추가합니다. 단, 3번째 인자로 timeout이 들어가는데, 이 tcp_timeout_init 함수가 무엇인지만 잠깐 보겠습니다.
// include/net/tcp.h/tcp_timeout_init() :2319
static inline u32 tcp_timeout_init(struct sock *sk)
{
int timeout;
timeout = tcp_call_bpf(sk, BPF_SOCK_OPS_TIMEOUT_INIT, 0, NULL);
if (timeout <= 0)
timeout = TCP_TIMEOUT_INIT;
return timeout;
}
사실 bpf를 사용하지 않는다면 별 의미는 없어보입니다. tcp_call_bpf에서 -1을 반환할 것으로 보이고 결국 TCP_TIMEOUT_INIT (1HZ, 1000)이 지정될 것입니다.
다음은 inet_csk_reqsk_queue_hash_add입니다.
// net/ipv4/inet_connection_sock.c/inet_csk_reqsk_queue_hash_add() :924
void inet_csk_reqsk_queue_hash_add(struct sock *sk, struct request_sock *req,
unsigned long timeout)
{
reqsk_queue_hash_req(req, timeout);
inet_csk_reqsk_queue_added(sk);
}
5-15-1. reqsk_queue_hash_req
inet_csk_reqsk_queue_hash_add에서 호출하는 첫 번째 함수입니다.
// net/ipv4/inet_connection_sock.c/reqsk_queue_hash_req() : 910
static void reqsk_queue_hash_req(struct request_sock *req,
unsigned long timeout)
{
timer_setup(&req->rsk_timer, reqsk_timer_handler, TIMER_PINNED);
mod_timer(&req->rsk_timer, jiffies + timeout);
inet_ehash_insert(req_to_sk(req), NULL, NULL);
/* before letting lookups find us, make sure all req fields
* are committed to memory and refcnt initialized.
*/
smp_wmb();
refcount_set(&req->rsk_refcnt, 2 + 1);
}
첫 줄에서 timer_setup을 하는 것으로 보입니다. reqsk_timer_handler는 'net/ipv4/inet_connection_sock.c/reqsk_timer_handler():796'에 정의되어 있으며, timer가 expired됐을 때 실행할 callback함수라고 보시면 되겠습니다. 함수를 들여다보면 여러 조건을 체크한 뒤에 SYN | ACK을 retransmit (inet_rtx_syn_ack함수)하는 코드로 구성되어 있습니다. 그리고 우리가 예상하듯 timeout을 'TCP_TIME_INIT << req->num_timeout'을 하며 2배씩 늘려나가죠.
reqsk_timer_handler는 넘어가도록 하겠습니다.
mod_timer(&req->rsk_timer, jiffies + timeout);
jiffies는 시스템이 켜진 후, 몇 번의 timer interrupt가 발생했는지를 나타냅니다. 즉, mod_timer를 통해 jiffies + timeout값으로 변경함에 따라, 상대 값이었던 timeout을 시스템 절대 값인 jiffies + timeout으로 변경해준다고 볼 수 있겠습니다.
timer는 linux inside chapter 5에서 다루고 있습니다. 이 내용을 조만간 읽어보려고 하는데, 기회가 된다면 정리해보겠습니다.
다음은 inet_ehash_insert 함수입니다.
// net/ipv4/inet_hashtables.c/inet_ehash_insert() :561
/* Insert a socket into ehash, and eventually remove another one
* (The another one can be a SYN_RECV or TIMEWAIT)
* If an existing socket already exists, socket sk is not inserted,
* and sets found_dup_sk parameter to true.
*/
bool inet_ehash_insert(struct sock *sk, struct sock *osk, bool *found_dup_sk)
{
struct inet_hashinfo *hashinfo = sk->sk_prot->h.hashinfo;
struct hlist_nulls_head *list;
struct inet_ehash_bucket *head;
spinlock_t *lock;
bool ret = true;
WARN_ON_ONCE(!sk_unhashed(sk));
sk->sk_hash = sk_ehashfn(sk);
head = inet_ehash_bucket(hashinfo, sk->sk_hash);
list = &head->chain;
lock = inet_ehash_lockp(hashinfo, sk->sk_hash);
spin_lock(lock);
if (osk) {
WARN_ON_ONCE(sk->sk_hash != osk->sk_hash);
ret = sk_nulls_del_node_init_rcu(osk);
} else if (found_dup_sk) {
*found_dup_sk = inet_ehash_lookup_by_sk(sk, list);
if (*found_dup_sk)
ret = false;
}
if (ret)
__sk_nulls_add_node_rcu(sk, list);
spin_unlock(lock);
return ret;
}
hash가 다시 등장합니다. bind때에는 bhash를 썼었는데요, 이번에는 ehash입니다.
- sk->sk_hash에는 hash값이 기록됩니다.
- head = inet_ehash_bucket(hashinfo, sk->sk_hash)는 protocol 별로 존재하는 hashtable->ehash에서 sk_hash번째 bucket을 가져옵니다.
- 그 밑의 두 줄은 chain을 얻어오고, bucket에 lock을 거는 역할을 수행합니다.
if 문에서는 osk가 NULL이므로 그 else if를 실행합니다.
// net/ipv4/inet_hashtables.c/inet_ehash_insert() :581
*found_dup_sk = inet_ehash_lookup_by_sk(sk, list);
if (*found_dup_sk)
ret = false;
inet_ehash_lookup_by_sk는 sk의 sk_dport, sk_daddr, sk_rcv_saddr, sk_num, 즉 4-tuple을 이용해서 같은 sk가 이미 list에 존재하는지 확인하는 함수입니다. 만약 중복된다면 true를 반환하고, 중복되지 않는다면 false를 반환합니다.
// net/ipv4/inet_hashtables.c/inet_ehash_looup_by_sk() :519
/* Searches for an exsiting socket in the ehash bucket list.
* Returns true if found, false otherwise.
*/
static bool inet_ehash_lookup_by_sk(struct sock *sk,
struct hlist_nulls_head *list)
{
const __portpair ports = INET_COMBINED_PORTS(sk->sk_dport, sk->sk_num);
const int sdif = sk->sk_bound_dev_if;
const int dif = sk->sk_bound_dev_if;
const struct hlist_nulls_node *node;
struct net *net = sock_net(sk);
struct sock *esk;
INET_ADDR_COOKIE(acookie, sk->sk_daddr, sk->sk_rcv_saddr);
sk_nulls_for_each_rcu(esk, node, list) {
if (esk->sk_hash != sk->sk_hash)
continue;
if (sk->sk_family == AF_INET) {
if (unlikely(INET_MATCH(esk, net, acookie,
sk->sk_daddr,
sk->sk_rcv_saddr,
ports, dif, sdif))) {
return true;
}
}
#if IS_ENABLED(CONFIG_IPV6)
else if (sk->sk_family == AF_INET6) {
if (unlikely(INET6_MATCH(esk, net,
&sk->sk_v6_daddr,
&sk->sk_v6_rcv_saddr,
ports, dif, sdif))) {
return true;
}
}
#endif
}
return false;
}
즉, 정상적인 케이스라면 false를 반환할 것입니다.
그렇다면 해당 함수 종료 후에 *found_dup_sk 값은 false로 지정이 될 것이고, 그에 따라 if(ret)는 true가 되어 __sk_nuls_add_node_rcu를 실행하게 됩니다.
// include/net/sock.h/__sk_nulls_add_node_rc() :777
static inline void __sk_nulls_add_node_rcu(struct sock *sk, struct hlist_nulls_head *list)
{
hlist_nulls_add_head_rcu(&sk->sk_nulls_node, list);
}
해당 함수는 sk의 sk_nulls_node를 list (sk->sk_hash->ehash->chain)에 추가합니다.
그리고 마지막으로 req->rsk_refcnt를 3으로 설정하면서 reqsk_queue_hash_req를 종료합니다.
5-15-2. inet_csk_reqsk_queue_added
// include/net/inet_connection_sock.h/inet_csk_reqsk_queue_added() :270
static inline void inet_csk_reqsk_queue_added(struct sock *sk)
{
reqsk_queue_added(&inet_csk(sk)->icsk_accept_queue);
}
// include/net/request_sock.h/reqsk_queue_added() :223
static inline void reqsk_queue_added(struct request_sock_queue *queue)
{
atomic_inc(&queue->young);
atomic_inc(&queue->qlen);
}
위 함수는 icsk_accept_queue의 young과 qlen의 값을 1씩 증가시킵니다. young이 무슨 역할을 할지는 아직 모르겠습니다.
5-16. send_synack
// net/ipv4/tcp_input.c/tcp_conn_request() :6928
af_ops->send_synack(sk, dst, &fl, req, &foc,
!want_cookie ? TCP_SYNACK_NORMAL :
TCP_SYNACK_COOKIE,
skb);
SYN | ACK 을 전송합니다. 해당 과정은 별도의 포스트에서 간단히 다뤄보도록 하고, 여기서는 스킵하겠습니다.
5-17. reqsk_put
마지막으로 req의 refcnt를 감소시키고 끝냅니다. 아래는 마지막에 출력해본 reqsk 값들입니다.

최종 흐름도
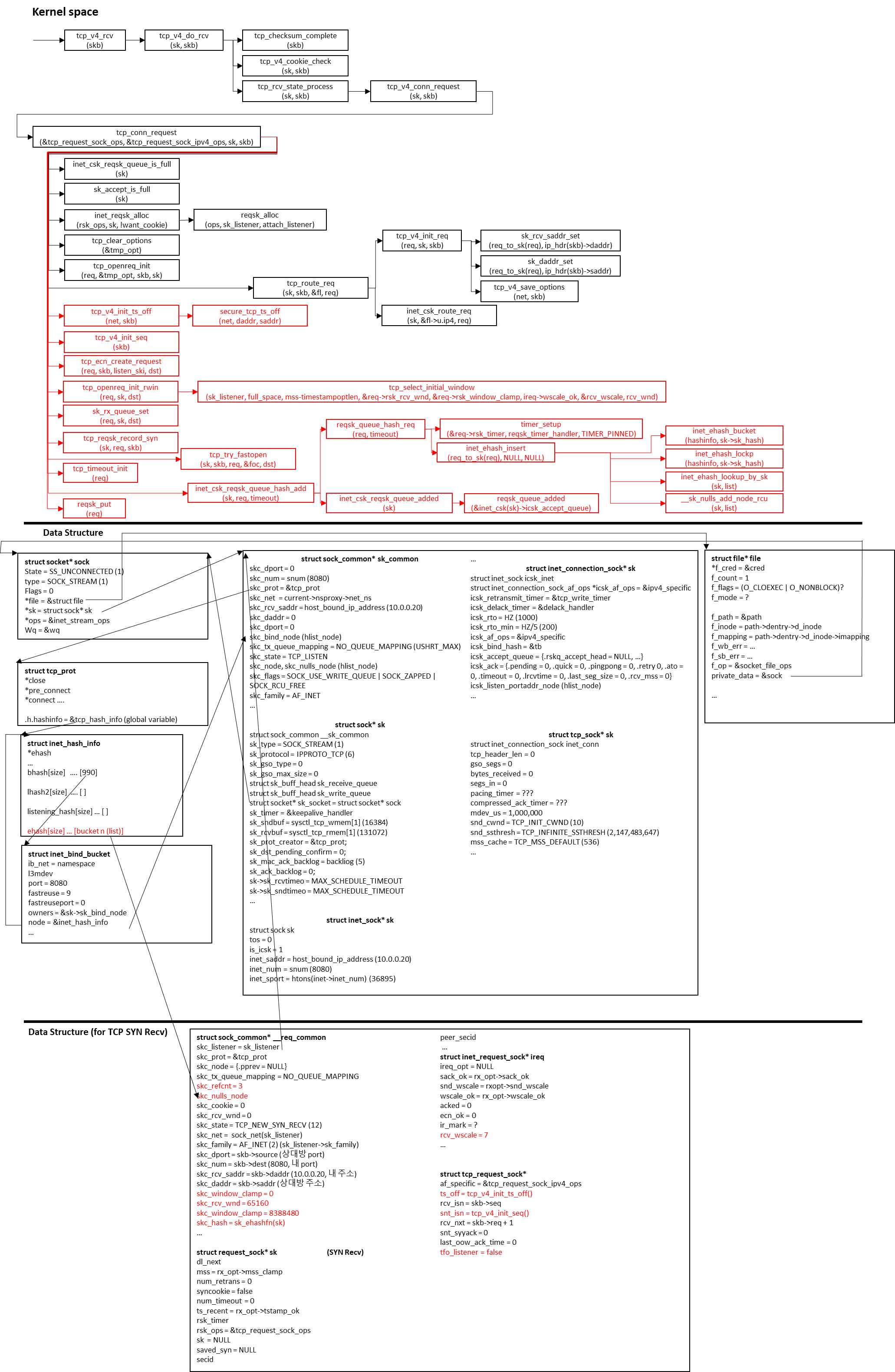
'프로그래밍 (Programming) > 네트워크 스택' 카테고리의 다른 글
| TCP SYN_RECV state의 ACK 처리 1 (0) | 2024.06.02 |
|---|---|
| Listen socket의 TCP SYN 처리 1 (0) | 2024.05.25 |
| ftrace 사용법 (0) | 2024.05.23 |
| accept system call 3 (inet_accept) (0) | 2024.05.19 |
| [Linux Kernel] Blocking I/O (0) | 2024.05.17 |


