
- Today
- Total
Byeo
Listen socket의 TCP SYN 처리 1 본문
accept system call은 established된 connection에 대해서 fd를 할당해 userspace에게 제공합니다.
그러면 3-way handshake의 TCP_SYN은 누가 처리할까요? 한 번 그 과정을 알아봅니다.
단, tcp code만 살펴볼 예정이고, device driver와 ip layer는 스킵합니다. 나중에 read system call에서 깊이 다루게 될 것 같습니다.
★ 이 로직은 application에 의해서 trigger되는 로직이 아닙니다! NIC이 packet을 수신하여 interrupt가 발생했고, device driver가 이를 처리하기 위해 trigger되는 로직(으로 예상을 하고있고, 나중에 read에서 확인할 예정)입니다!
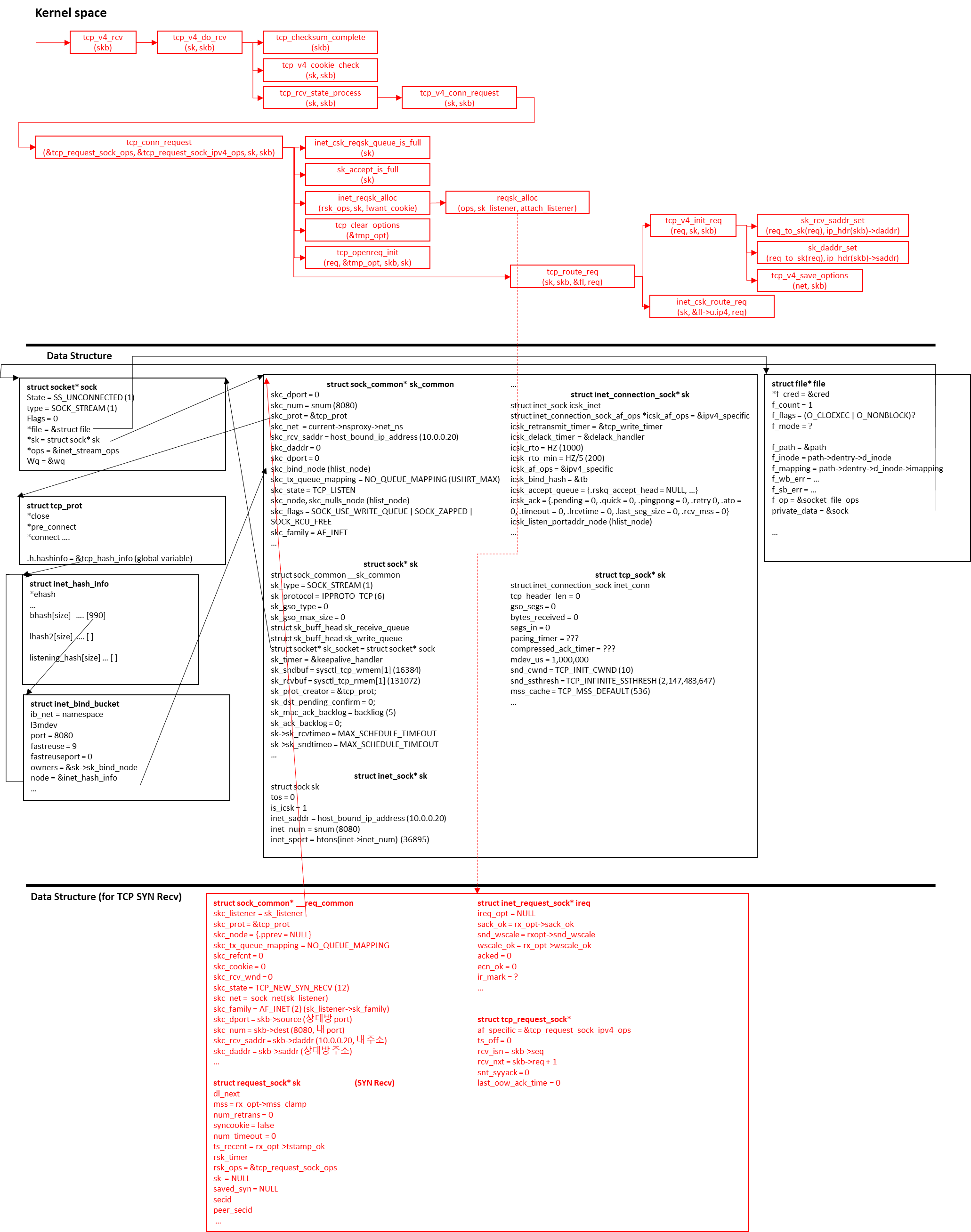
1. tcp_v4_rcv
tcp_v4_rcv라는 함수는 인자로 sk_buff* skb를 받아서 tcp 수신 처리를 진행합니다. 이 함수에서 sk->sk_state가 TCP_LISTEN인지를 체크하는 코드가 있습니다.
// net/ipv4/tcp_ipv4.c/tcp_v4_rcv() :2093
if (sk->sk_state == TCP_LISTEN) { printk("[byeo: tcp_v4_rcv] sk ptr %p\n", sk->sk_socket);
ret = tcp_v4_do_rcv(sk, skb);
goto put_and_return;
}
이 if문을 타는지 한 번 체크하기 위해서 printk를 넣어보았습니다.

socket() 당시 할당받았던 struct sock*과 tcp_v4_rcv에서 찍은 struct sock*의 pointer가 같으므로 같은 socket이라고 볼 수 있겠군요. 결국은 저 if branch를 탄다는 것을 확인했습니다.
- Linex kernel에서 fd를 struct file으로 바꾸는 함수는 있으나, struct file을 fd로 바꾸는 함수는 찾지 못했습니다. 만약 그런 함수가 있다면 sk->sk_socket->file 을 fd로 바꿔서 비교해볼텐데 말이죠.. 혹시 좋은 방법이 있다면 공유부탁드립니다~
2. tcp_v4_do_rcv
// net/ipv4/tcp_ipv4.c/tcp_v4_do_rcv() :1696
/* The socket must have it's spinlock held when we get
* here, unless it is a TCP_LISTEN socket.
*
* We have a potential double-lock case here, so even when
* doing backlog processing we use the BH locking scheme.
* This is because we cannot sleep with the original spinlock
* held.
*/
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
struct sock *rsk;
if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
struct dst_entry *dst = sk->sk_rx_dst;
sock_rps_save_rxhash(sk, skb);
sk_mark_napi_id(sk, skb);
if (dst) {
if (inet_sk(sk)->rx_dst_ifindex != skb->skb_iif ||
!INDIRECT_CALL_1(dst->ops->check, ipv4_dst_check,
dst, 0)) {
dst_release(dst);
sk->sk_rx_dst = NULL;
}
}
tcp_rcv_established(sk, skb);
return 0;
}
if (tcp_checksum_complete(skb))
goto csum_err;
if (sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_cookie_check(sk, skb);
if (!nsk)
goto discard;
if (nsk != sk) {
if (tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
} else
sock_rps_save_rxhash(sk, skb);
if (tcp_rcv_state_process(sk, skb)) {
rsk = sk;
goto reset;
}
return 0;
reset:
tcp_v4_send_reset(rsk, skb);
discard:
kfree_skb(skb);
/* Be careful here. If this function gets more complicated and
* gcc suffers from register pressure on the x86, sk (in %ebx)
* might be destroyed here. This current version compiles correctly,
* but you have been warned.
*/
return 0;
csum_err:
trace_tcp_bad_csum(skb);
TCP_INC_STATS(sock_net(sk), TCP_MIB_CSUMERRORS);
TCP_INC_STATS(sock_net(sk), TCP_MIB_INERRS);
goto discard;
}
EXPORT_SYMBOL(tcp_v4_do_rcv);
tcp_v4_do_rcv 함수입니다. sk->sk_state == TCP_ESTABLISHED는 건너 뛰겠습니다.
if (tcp_checksum_complete(skb))
goto csum_err;
체크섬을 검사하는 항목입니다. skb의 구조체를 확인해 checksum 연산이 필요한지 확인하고, 필요하면 checksum 검사를 실행합니다.
2-1. tcp_v4_cookie_check
// net/ipv4/tcp_ipv4.c/tcp_v4_cookie_check() :1660
static struct sock *tcp_v4_cookie_check(struct sock *sk, struct sk_buff *skb)
{
#ifdef CONFIG_SYN_COOKIES
const struct tcphdr *th = tcp_hdr(skb);
if (!th->syn)
sk = cookie_v4_check(sk, skb);
#endif
return sk;
}
TCP SYN_COOKIE와 관련이 있는 함수입니다. syn cookie는 ddos 공격인 syn flooding을 방지하기 위해서 추가된 기능인데요. SYN-ACK의 #seq에 magic number를 넣어서 (1) SYN queue를 제거하면서도 (2) SYN이 왔었음을 간주하는 방법입니다.
여기서는 3-way handshake에서 client가 보낸 3rd ACK packet의 ack 값이 올바른지를 확인합니다. 자세한 내용은 넘기겠습니다.
SYN_COOKIES관련 로직은 스킵하겠습니다.
이 현재 SYN packet이므로 sk를 return할 것이고, nsk와 sk가 같으므로 1726 줄 (tcp_child_process)은 실행하지 않습니다.
3. tcp_rcv_state_process
그러면 tcp_v4_do_rcv가 다음으로 실행하는 함수는 tcp_rcv_state_process입니다.
// net/ipv4/tcp_input.c/tcp_fcv_state_process() :6354
/*
* This function implements the receiving procedure of RFC 793 for
* all states except ESTABLISHED and TIME_WAIT.
* It's called from both tcp_v4_rcv and tcp_v6_rcv and should be
* address independent.
*/
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb);
struct request_sock *req;
int queued = 0;
bool acceptable;
switch (sk->sk_state) {
case TCP_CLOSE:
goto discard;
case TCP_LISTEN:
if (th->ack)
return 1;
if (th->rst)
goto discard;
if (th->syn) {
if (th->fin)
goto discard;
/* It is possible that we process SYN packets from backlog,
* so we need to make sure to disable BH and RCU right there.
*/
rcu_read_lock();
local_bh_disable();
acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0;
local_bh_enable();
rcu_read_unlock();
if (!acceptable)
return 1;
consume_skb(skb);
return 0;
}
goto discard;
case TCP_SYN_SENT:
tp->rx_opt.saw_tstamp = 0;
tcp_mstamp_refresh(tp);
queued = tcp_rcv_synsent_state_process(sk, skb, th);
if (queued >= 0)
return queued;
/* Do step6 onward by hand. */
tcp_urg(sk, skb, th);
__kfree_skb(skb);
tcp_data_snd_check(sk);
return 0;
}
tcp_mstamp_refresh(tp);
tp->rx_opt.saw_tstamp = 0;
req = rcu_dereference_protected(tp->fastopen_rsk,
lockdep_sock_is_held(sk));
if (req) {
bool req_stolen;
WARN_ON_ONCE(sk->sk_state != TCP_SYN_RECV &&
sk->sk_state != TCP_FIN_WAIT1);
if (!tcp_check_req(sk, skb, req, true, &req_stolen))
goto discard;
}
if (!th->ack && !th->rst && !th->syn)
goto discard;
if (!tcp_validate_incoming(sk, skb, th, 0))
return 0;
/* step 5: check the ACK field */
acceptable = tcp_ack(sk, skb, FLAG_SLOWPATH |
FLAG_UPDATE_TS_RECENT |
FLAG_NO_CHALLENGE_ACK) > 0;
if (!acceptable) {
if (sk->sk_state == TCP_SYN_RECV)
return 1; /* send one RST */
tcp_send_challenge_ack(sk, skb);
goto discard;
}
switch (sk->sk_state) {
case TCP_SYN_RECV:
tp->delivered++; /* SYN-ACK delivery isn't tracked in tcp_ack */
if (!tp->srtt_us)
tcp_synack_rtt_meas(sk, req);
if (req) {
tcp_rcv_synrecv_state_fastopen(sk);
} else {
tcp_try_undo_spurious_syn(sk);
tp->retrans_stamp = 0;
tcp_init_transfer(sk, BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB,
skb);
WRITE_ONCE(tp->copied_seq, tp->rcv_nxt);
}
smp_mb();
tcp_set_state(sk, TCP_ESTABLISHED);
sk->sk_state_change(sk);
/* Note, that this wakeup is only for marginal crossed SYN case.
* Passively open sockets are not waked up, because
* sk->sk_sleep == NULL and sk->sk_socket == NULL.
*/
if (sk->sk_socket)
sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT);
tp->snd_una = TCP_SKB_CB(skb)->ack_seq;
tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale;
tcp_init_wl(tp, TCP_SKB_CB(skb)->seq);
if (tp->rx_opt.tstamp_ok)
tp->advmss -= TCPOLEN_TSTAMP_ALIGNED;
if (!inet_csk(sk)->icsk_ca_ops->cong_control)
tcp_update_pacing_rate(sk);
/* Prevent spurious tcp_cwnd_restart() on first data packet */
tp->lsndtime = tcp_jiffies32;
tcp_initialize_rcv_mss(sk);
tcp_fast_path_on(tp);
break;
case TCP_FIN_WAIT1: {
int tmo;
if (req)
tcp_rcv_synrecv_state_fastopen(sk);
if (tp->snd_una != tp->write_seq)
break;
tcp_set_state(sk, TCP_FIN_WAIT2);
sk->sk_shutdown |= SEND_SHUTDOWN;
sk_dst_confirm(sk);
if (!sock_flag(sk, SOCK_DEAD)) {
/* Wake up lingering close() */
sk->sk_state_change(sk);
break;
}
if (tp->linger2 < 0) {
tcp_done(sk);
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA);
return 1;
}
if (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq &&
after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt)) {
/* Receive out of order FIN after close() */
if (tp->syn_fastopen && th->fin)
tcp_fastopen_active_disable(sk);
tcp_done(sk);
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA);
return 1;
}
tmo = tcp_fin_time(sk);
if (tmo > TCP_TIMEWAIT_LEN) {
inet_csk_reset_keepalive_timer(sk, tmo - TCP_TIMEWAIT_LEN);
} else if (th->fin || sock_owned_by_user(sk)) {
/* Bad case. We could lose such FIN otherwise.
* It is not a big problem, but it looks confusing
* and not so rare event. We still can lose it now,
* if it spins in bh_lock_sock(), but it is really
* marginal case.
*/
inet_csk_reset_keepalive_timer(sk, tmo);
} else {
tcp_time_wait(sk, TCP_FIN_WAIT2, tmo);
goto discard;
}
break;
}
case TCP_CLOSING:
if (tp->snd_una == tp->write_seq) {
tcp_time_wait(sk, TCP_TIME_WAIT, 0);
goto discard;
}
break;
case TCP_LAST_ACK:
if (tp->snd_una == tp->write_seq) {
tcp_update_metrics(sk);
tcp_done(sk);
goto discard;
}
break;
}
/* step 6: check the URG bit */
tcp_urg(sk, skb, th);
/* step 7: process the segment text */
switch (sk->sk_state) {
case TCP_CLOSE_WAIT:
case TCP_CLOSING:
case TCP_LAST_ACK:
if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) {
/* If a subflow has been reset, the packet should not
* continue to be processed, drop the packet.
*/
if (sk_is_mptcp(sk) && !mptcp_incoming_options(sk, skb))
goto discard;
break;
}
fallthrough;
case TCP_FIN_WAIT1:
case TCP_FIN_WAIT2:
/* RFC 793 says to queue data in these states,
* RFC 1122 says we MUST send a reset.
* BSD 4.4 also does reset.
*/
if (sk->sk_shutdown & RCV_SHUTDOWN) {
if (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq &&
after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA);
tcp_reset(sk, skb);
return 1;
}
}
fallthrough;
case TCP_ESTABLISHED:
tcp_data_queue(sk, skb);
queued = 1;
break;
}
/* tcp_data could move socket to TIME-WAIT */
if (sk->sk_state != TCP_CLOSE) {
tcp_data_snd_check(sk);
tcp_ack_snd_check(sk);
}
if (!queued) {
discard:
tcp_drop(sk, skb);
}
return 0;
}
EXPORT_SYMBOL(tcp_rcv_state_process);
길지만 볼 내용은 사실 짧은 함수입니다.
case TCP_LISTEN:
if (th->ack)
return 1;
if (th->rst)
goto discard;
if (th->syn) {
if (th->fin)
goto discard;
/* It is possible that we process SYN packets from backlog,
* so we need to make sure to disable BH and RCU right there.
*/
rcu_read_lock();
local_bh_disable();
acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0;
local_bh_enable();
rcu_read_unlock();
if (!acceptable)
return 1;
consume_skb(skb);
return 0;
}
goto discard;
th->ack라면 1을 return하여 tcp_v4_do_rcv의 tcp_v4_send_reset을 호출하게 합니다. 즉, rst packet을 보낼 것으로 보입니다. LISTEN상태인데 ack가 먼저 오는 것은 말이 안되죠.
th->rst라면 discard label로 이동해서 tcp_drop을 호출합니다. tcp_drop은 sk->drop 바이트를 증가시키고 (통계목적으로 사용할 것으로 추측됩니다.) skb_free를 실행합니다.
th->syn이고 th->fin이 아니라면 icsk->icsk_af_ops->conn_request(sk, skb)를 실행합니다.
socket() 에 의해서 tcp_v4_init_sock이 호출된 적이 있고, 그에 따라 icsk->icsk_af_ops는 ipv4_specific으로 지정되었었습니다.
// net/ipv4/tcp_ipv4.c:2209
const struct inet_connection_sock_af_ops ipv4_specific = {
.queue_xmit = ip_queue_xmit,
.send_check = tcp_v4_send_check,
.rebuild_header = inet_sk_rebuild_header,
.sk_rx_dst_set = inet_sk_rx_dst_set,
.conn_request = tcp_v4_conn_request,
.syn_recv_sock = tcp_v4_syn_recv_sock,
.net_header_len = sizeof(struct iphdr),
.setsockopt = ip_setsockopt,
.getsockopt = ip_getsockopt,
.addr2sockaddr = inet_csk_addr2sockaddr,
.sockaddr_len = sizeof(struct sockaddr_in),
.mtu_reduced = tcp_v4_mtu_reduced,
};
EXPORT_SYMBOL(ipv4_specific);
conn_request는 tcp_v4_conn_request함수로 지정이 되어있네요!
4. tcp_v4_conn_request
// net/ipv4/tcp_ipv4.c/tcp_v4_conn_request() :1519
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
/* Never answer to SYNs send to broadcast or multicast */
if (skb_rtable(skb)->rt_flags & (RTCF_BROADCAST | RTCF_MULTICAST))
goto drop;
return tcp_conn_request(&tcp_request_sock_ops,
&tcp_request_sock_ipv4_ops, sk, skb);
drop:
tcp_listendrop(sk);
return 0;
}
첫 if문은 주석에 적혀있듯, broadcast 및 multicast packet에는 응답을 하지 않도록 하는 코드입니다.
바로 tcp_conn_request를 호출합니다.
5. tcp_conn_request
// net/ipv4/tcp_input.c/tcp_conn_request() :6804
int tcp_conn_request(struct request_sock_ops *rsk_ops,
const struct tcp_request_sock_ops *af_ops,
struct sock *sk, struct sk_buff *skb)
{
struct tcp_fastopen_cookie foc = { .len = -1 };
__u32 isn = TCP_SKB_CB(skb)->tcp_tw_isn;
struct tcp_options_received tmp_opt;
struct tcp_sock *tp = tcp_sk(sk);
struct net *net = sock_net(sk);
struct sock *fastopen_sk = NULL;
struct request_sock *req;
bool want_cookie = false;
struct dst_entry *dst;
struct flowi fl;
/* TW buckets are converted to open requests without
* limitations, they conserve resources and peer is
* evidently real one.
*/
if ((net->ipv4.sysctl_tcp_syncookies == 2 ||
inet_csk_reqsk_queue_is_full(sk)) && !isn) {
want_cookie = tcp_syn_flood_action(sk, rsk_ops->slab_name);
if (!want_cookie)
goto drop;
}
if (sk_acceptq_is_full(sk)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
req = inet_reqsk_alloc(rsk_ops, sk, !want_cookie);
if (!req)
goto drop;
req->syncookie = want_cookie;
tcp_rsk(req)->af_specific = af_ops;
tcp_rsk(req)->ts_off = 0;
#if IS_ENABLED(CONFIG_MPTCP)
tcp_rsk(req)->is_mptcp = 0;
#endif
tcp_clear_options(&tmp_opt);
tmp_opt.mss_clamp = af_ops->mss_clamp;
tmp_opt.user_mss = tp->rx_opt.user_mss;
tcp_parse_options(sock_net(sk), skb, &tmp_opt, 0,
want_cookie ? NULL : &foc);
if (want_cookie && !tmp_opt.saw_tstamp)
tcp_clear_options(&tmp_opt);
if (IS_ENABLED(CONFIG_SMC) && want_cookie)
tmp_opt.smc_ok = 0;
tmp_opt.tstamp_ok = tmp_opt.saw_tstamp;
tcp_openreq_init(req, &tmp_opt, skb, sk);
inet_rsk(req)->no_srccheck = inet_sk(sk)->transparent;
/* Note: tcp_v6_init_req() might override ir_iif for link locals */
inet_rsk(req)->ir_iif = inet_request_bound_dev_if(sk, skb);
dst = af_ops->route_req(sk, skb, &fl, req);
if (!dst)
goto drop_and_free;
if (tmp_opt.tstamp_ok)
tcp_rsk(req)->ts_off = af_ops->init_ts_off(net, skb);
if (!want_cookie && !isn) {
/* Kill the following clause, if you dislike this way. */
if (!net->ipv4.sysctl_tcp_syncookies &&
(net->ipv4.sysctl_max_syn_backlog - inet_csk_reqsk_queue_len(sk) <
(net->ipv4.sysctl_max_syn_backlog >> 2)) &&
!tcp_peer_is_proven(req, dst)) {
/* Without syncookies last quarter of
* backlog is filled with destinations,
* proven to be alive.
* It means that we continue to communicate
* to destinations, already remembered
* to the moment of synflood.
*/
pr_drop_req(req, ntohs(tcp_hdr(skb)->source),
rsk_ops->family);
goto drop_and_release;
}
isn = af_ops->init_seq(skb);
}
tcp_ecn_create_request(req, skb, sk, dst);
if (want_cookie) {
isn = cookie_init_sequence(af_ops, sk, skb, &req->mss);
if (!tmp_opt.tstamp_ok)
inet_rsk(req)->ecn_ok = 0;
}
tcp_rsk(req)->snt_isn = isn;
tcp_rsk(req)->txhash = net_tx_rndhash();
tcp_rsk(req)->syn_tos = TCP_SKB_CB(skb)->ip_dsfield;
tcp_openreq_init_rwin(req, sk, dst);
sk_rx_queue_set(req_to_sk(req), skb);
if (!want_cookie) {
tcp_reqsk_record_syn(sk, req, skb);
fastopen_sk = tcp_try_fastopen(sk, skb, req, &foc, dst);
}
if (fastopen_sk) {
af_ops->send_synack(fastopen_sk, dst, &fl, req,
&foc, TCP_SYNACK_FASTOPEN, skb);
/* Add the child socket directly into the accept queue */
if (!inet_csk_reqsk_queue_add(sk, req, fastopen_sk)) {
reqsk_fastopen_remove(fastopen_sk, req, false);
bh_unlock_sock(fastopen_sk);
sock_put(fastopen_sk);
goto drop_and_free;
}
sk->sk_data_ready(sk);
bh_unlock_sock(fastopen_sk);
sock_put(fastopen_sk);
} else {
tcp_rsk(req)->tfo_listener = false;
if (!want_cookie)
inet_csk_reqsk_queue_hash_add(sk, req,
tcp_timeout_init((struct sock *)req));
af_ops->send_synack(sk, dst, &fl, req, &foc,
!want_cookie ? TCP_SYNACK_NORMAL :
TCP_SYNACK_COOKIE,
skb);
if (want_cookie) {
reqsk_free(req);
return 0;
}
}
reqsk_put(req);
return 0;
drop_and_release:
dst_release(dst);
drop_and_free:
__reqsk_free(req);
drop:
tcp_listendrop(sk);
return 0;
}
EXPORT_SYMBOL(tcp_conn_request);
함수를 한 번 훑어보면 알겠지만 명시적으로 skc->state를 TCP_SYN_RECV로 변경하는 로직은 없습니다. tcp diagram을 보면 SYN을 수신 시, TCP_SYN_RECV로 변경된다고 그려져 있습니다. 하지만 실제로 tcp_set_state함수를 전체 검색해보면 TCP_SYN_RECV로 변경하는 경우는 tcp simultaneous open말고 없었습니다.
- 대신에, SYN packet을 수신하면 reqsk를 새로 할당할 때 TCP_NEW_SYN_RECV state로 관리하며, listen socket의 SYN queue에 보관합니다. 이들을 SYN_RECV라고 볼 수 있겠습니다.
혹시나 코드 해석에 문제가 있는 것은 아니었을까 해서 검색해본 결과 몇 가지 자료를 찾을 수 있었습니다. 1 2
5-1. inet_csk_reqsk_queue_is_full
// net/ipv4/tcp_input.c/tcp_conn_request() :6823
if ((net->ipv4.sysctl_tcp_syncookies == 2 ||
inet_csk_reqsk_queue_is_full(sk)) && !isn) {
want_cookie = tcp_syn_flood_action(sk, rsk_ops->slab_name);
if (!want_cookie)
goto drop;
}
syn_cookie 설정값과 accept_queue가 꽉 찼는지 확인합니다.
- sysctl_tcp_syncookies의 설정값에 대한 의미는 다른 블로그에서 잘 정리해두었습니다. 3
- sysctl에서 tcp_syncookie가 2인 경우에는 accept queue (reqsk)의 상태와 관계없이 syncookie를 발행합니다.
- sysctl에서 tcp_syncookie가 1인 경우에는 accept queue가 꽉찼을 때에만 syncookie를 발행합니다.
아래는 inet_csk_reqsk_queue_is_full 함수입니다.
// include/net/inet_connection_sock.h :275
static inline int inet_csk_reqsk_queue_len(const struct sock *sk)
{
return reqsk_queue_len(&inet_csk(sk)->icsk_accept_queue);
}
static inline int inet_csk_reqsk_queue_is_full(const struct sock *sk)
{
return inet_csk_reqsk_queue_len(sk) >= sk->sk_max_ack_backlog;
}
5-2. sk_acceptq_is_full
// net/ipv4/tcp_input.c/tcp_conn_request() :6830
if (sk_acceptq_is_full(sk)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
// include/net/sock.h/sk_acceptq_is_full() :948
static inline bool sk_acceptq_is_full(const struct sock *sk)
{
return READ_ONCE(sk->sk_ack_backlog) > READ_ONCE(sk->sk_max_ack_backlog);
}
sk->ack_backlog가 꽉 찼다면 (listen 당시 주어진 backlog 값을 넘겼다면), 통계를 처리하고 drop처리합니다.
5-3. inet_reqsk_alloc
// net/ipv4/tcp_input.c/tcp_conn_request() :6835
req = inet_reqsk_alloc(rsk_ops, sk, !want_cookie);
if (!req)
goto drop;
reqsk를 할당합니다. 해당 함수는 다음과같이 정의되어 있습니다. syn cookie가 아닌 상황을 가정할 것이므로, want_cookie는 false고 !want_cookie는 true라고 가정합니다.
// net/ipv4/tcp_input.c/inet_reqsk_alloc() :6691
struct request_sock *inet_reqsk_alloc(const struct request_sock_ops *ops,
struct sock *sk_listener,
bool attach_listener)
{
struct request_sock *req = reqsk_alloc(ops, sk_listener,
attach_listener);
if (req) {
struct inet_request_sock *ireq = inet_rsk(req);
ireq->ireq_opt = NULL;
#if IS_ENABLED(CONFIG_IPV6)
ireq->pktopts = NULL;
#endif
atomic64_set(&ireq->ir_cookie, 0);
ireq->ireq_state = TCP_NEW_SYN_RECV;
write_pnet(&ireq->ireq_net, sock_net(sk_listener));
ireq->ireq_family = sk_listener->sk_family;
}
return req;
}
EXPORT_SYMBOL(inet_reqsk_alloc);
reqsk_alloc함수를 통해 request_sock 자료구조를 할당합니다. 그리고 몇 가지 초기화를 진행합니다.
5-3-1. reqsk_alloc
// include/net/request_sock.h/reqsk_alloc() :85
static inline struct request_sock *
reqsk_alloc(const struct request_sock_ops *ops, struct sock *sk_listener,
bool attach_listener)
{
struct request_sock *req;
req = kmem_cache_alloc(ops->slab, GFP_ATOMIC | __GFP_NOWARN);
if (!req)
return NULL;
req->rsk_listener = NULL;
if (attach_listener) {
if (unlikely(!refcount_inc_not_zero(&sk_listener->sk_refcnt))) {
kmem_cache_free(ops->slab, req);
return NULL;
}
req->rsk_listener = sk_listener;
}
req->rsk_ops = ops;
req_to_sk(req)->sk_prot = sk_listener->sk_prot;
sk_node_init(&req_to_sk(req)->sk_node);
sk_tx_queue_clear(req_to_sk(req));
req->saved_syn = NULL;
req->num_timeout = 0;
req->num_retrans = 0;
req->sk = NULL;
refcount_set(&req->rsk_refcnt, 0);
return req;
}
이 함수는 실제로 kernel 내 메모리 공간을 할당합니다.
- attach_listener는 true이므로 req->rsk_listener에 listen socket sk가 붙습니다.
- rsk_ops는 tcp_conn_request에서 넘어온 &tcp_request_sock_ops가 붙습니다.
- sk_prot는 listen socket의 sk_prot인 &tcp_prot를 가져옵니다.
- 그 외 몇몇 변수들을 초기화 합니다.
5-3-2. request_sock 구조체
request sock 구조체 자료구조는 다음과 같이 생겼습니다.
// include/net/request_sock.h :51
/* struct request_sock - mini sock to represent a connection request
*/
struct request_sock {
struct sock_common __req_common;
#define rsk_refcnt __req_common.skc_refcnt
#define rsk_hash __req_common.skc_hash
#define rsk_listener __req_common.skc_listener
#define rsk_window_clamp __req_common.skc_window_clamp
#define rsk_rcv_wnd __req_common.skc_rcv_wnd
struct request_sock *dl_next;
u16 mss;
u8 num_retrans; /* number of retransmits */
u8 syncookie:1; /* syncookie: encode tcpopts in timestamp */
u8 num_timeout:7; /* number of timeouts */
u32 ts_recent;
struct timer_list rsk_timer;
const struct request_sock_ops *rsk_ops;
struct sock *sk;
struct saved_syn *saved_syn;
u32 secid;
u32 peer_secid;
};
5-4. inet_reqsk_alloc에서 초기화 더 수행
// net/ipv4/tcp_input.c/inet_reqsk_alloc() :6691
if (req) {
struct inet_request_sock *ireq = inet_rsk(req);
ireq->ireq_opt = NULL;
#if IS_ENABLED(CONFIG_IPV6)
ireq->pktopts = NULL;
#endif
atomic64_set(&ireq->ir_cookie, 0);
ireq->ireq_state = TCP_NEW_SYN_RECV;
write_pnet(&ireq->ireq_net, sock_net(sk_listener));
ireq->ireq_family = sk_listener->sk_family;
}
이제 reqsk_alloc을 통해 공간을 할당 받았고 몇몇개는 초기화 했습니다. 남은 요소들을 추가로 초기화합니다.
대부분 listener sock에 있던 데이터들을 가져옵니다. sk_family와 같은 경우는 socket() system call에서 AF_INET으로 초기화가 됐었습니다.
inet_rsk는 request_sock을 inet_request_sock으로 타입을 확장합니다. inet_request_sock 구조체는 다음과 같이 생겼습니다.
5-4-1. inet_request_sock 구조체
// include/net/inet_sock.h :68
struct inet_request_sock {
struct request_sock req;
#define ir_loc_addr req.__req_common.skc_rcv_saddr
#define ir_rmt_addr req.__req_common.skc_daddr
#define ir_num req.__req_common.skc_num
#define ir_rmt_port req.__req_common.skc_dport
#define ir_v6_rmt_addr req.__req_common.skc_v6_daddr
#define ir_v6_loc_addr req.__req_common.skc_v6_rcv_saddr
#define ir_iif req.__req_common.skc_bound_dev_if
#define ir_cookie req.__req_common.skc_cookie
#define ireq_net req.__req_common.skc_net
#define ireq_state req.__req_common.skc_state
#define ireq_family req.__req_common.skc_family
u16 snd_wscale : 4,
rcv_wscale : 4,
tstamp_ok : 1,
sack_ok : 1,
wscale_ok : 1,
ecn_ok : 1,
acked : 1,
no_srccheck: 1,
smc_ok : 1;
u32 ir_mark;
union {
struct ip_options_rcu __rcu *ireq_opt;
#if IS_ENABLED(CONFIG_IPV6)
struct {
struct ipv6_txoptions *ipv6_opt;
struct sk_buff *pktopts;
};
#endif
};
};
5-5. tcp_conn_request로 돌아와서
// net/ipv4/tcp_input.c/tcp_conn_request() :6835
req = inet_reqsk_alloc(rsk_ops, sk, !want_cookie);
if (!req)
goto drop;
5-3~5-4를 통해서 inet_reqsk_alloc과정을 살펴봤습니다. 이제 남은 내용을 확인해봅니다.
// net/ipv4/tcp_input.c/tcp_conn_reqest() :6839
req->syncookie = want_cookie;
tcp_rsk(req)->af_specific = af_ops;
tcp_rsk(req)->ts_off = 0;
#if IS_ENABLED(CONFIG_MPTCP)
tcp_rsk(req)->is_mptcp = 0;
#endif
tcp_clear_options(&tmp_opt);
tmp_opt.mss_clamp = af_ops->mss_clamp;
tmp_opt.user_mss = tp->rx_opt.user_mss;
tcp_parse_options(sock_net(sk), skb, &tmp_opt, 0,
want_cookie ? NULL : &foc);
if (want_cookie && !tmp_opt.saw_tstamp)
tcp_clear_options(&tmp_opt);
if (IS_ENABLED(CONFIG_SMC) && want_cookie)
tmp_opt.smc_ok = 0;
tmp_opt.tstamp_ok = tmp_opt.saw_tstamp;
tcp_openreq_init(req, &tmp_opt, skb, sk);
inet_rsk(req)->no_srccheck = inet_sk(sk)->transparent;
syncookie에 want_cookie를 저장, tcp_rsk(req)에 몇몇 값들을 초기화합니다. tcp_rsk(req)는 마찬가지로 request sock을 tcp_request_sock구조체로 형변환을 한 것입니다.
tcp_request_sock 구조체는 다음과 같이 생겼습니다.
// include/linux/tcp.h :119
struct tcp_request_sock {
struct inet_request_sock req;
const struct tcp_request_sock_ops *af_specific;
u64 snt_synack; /* first SYNACK sent time */
bool tfo_listener;
bool is_mptcp;
#if IS_ENABLED(CONFIG_MPTCP)
bool drop_req;
#endif
u32 txhash;
u32 rcv_isn;
u32 snt_isn;
u32 ts_off;
u32 last_oow_ack_time; /* last SYNACK */
u32 rcv_nxt; /* the ack # by SYNACK. For
* FastOpen it's the seq#
* after data-in-SYN.
*/
u8 syn_tos;
};
mptcp는 multi-path tcp의 약자인데, 이 내용은 스킵하겠습니다.
tcpreqsk의 af_specific에는 tcp_conn_request에서 넘어온 &tcp_request_sock_ipv4가 붙습니다.
5-5-1. tcp options
// linux/tcp.h/tcp_clear_options() :102
static inline void tcp_clear_options(struct tcp_options_received *rx_opt)
{
rx_opt->tstamp_ok = rx_opt->sack_ok = 0;
rx_opt->wscale_ok = rx_opt->snd_wscale = 0;
#if IS_ENABLED(CONFIG_SMC)
rx_opt->smc_ok = 0;
#endif
}
tmp_opt 구조체의 값들을 초기화합니다.
그 아래 나오는 tcp_parse_options는 수신한 sk_buff에서 tcp_hdr에 붙은 option들을 parsing하여 분류해줍니다. 그리고 이를 tmp_opt 구조체에 값들을 넣어서 돌려줍니다.
tcp_parse_options(sock_net(sk), skb, &tmp_opt, 0,
want_cookie ? NULL : &foc);
그 다음은 want_cookie가 true이면서 saw_tstamp가 0인경우는 tmp_opt를 다시 초기화합니다. 현재 우리는 want_cookie를 false라고 가정하고 있으므로 넘어갑니다. (코드의 의미는 추후 확인 필요)
if (want_cookie && !tmp_opt.saw_tstamp)
tcp_clear_options(&tmp_opt);
if (IS_ENABLED(CONFIG_SMC) && want_cookie)
tmp_opt.smc_ok = 0;
5-5-2. tcp_openreq_init
수신된 packet의 tcp option을 가지고 몇몇 변수를 추가로 초기화합니다.
// net/ipv4/tcp_input.c/tcp_openreq_init() :6664
static void tcp_openreq_init(struct request_sock *req,
const struct tcp_options_received *rx_opt,
struct sk_buff *skb, const struct sock *sk)
{
struct inet_request_sock *ireq = inet_rsk(req);
req->rsk_rcv_wnd = 0; /* So that tcp_send_synack() knows! */
tcp_rsk(req)->rcv_isn = TCP_SKB_CB(skb)->seq;
tcp_rsk(req)->rcv_nxt = TCP_SKB_CB(skb)->seq + 1;
tcp_rsk(req)->snt_synack = 0;
tcp_rsk(req)->last_oow_ack_time = 0;
req->mss = rx_opt->mss_clamp;
req->ts_recent = rx_opt->saw_tstamp ? rx_opt->rcv_tsval : 0;
ireq->tstamp_ok = rx_opt->tstamp_ok;
ireq->sack_ok = rx_opt->sack_ok;
ireq->snd_wscale = rx_opt->snd_wscale;
ireq->wscale_ok = rx_opt->wscale_ok;
ireq->acked = 0;
ireq->ecn_ok = 0;
ireq->ir_rmt_port = tcp_hdr(skb)->source;
ireq->ir_num = ntohs(tcp_hdr(skb)->dest);
ireq->ir_mark = inet_request_mark(sk, skb);
#if IS_ENABLED(CONFIG_SMC)
ireq->smc_ok = rx_opt->smc_ok;
#endif
}
5-5-3. route_req
// net/ipv4/tcp_input.c/tcp_conn_request() :6862
/* Note: tcp_v6_init_req() might override ir_iif for link locals */
inet_rsk(req)->ir_iif = inet_request_bound_dev_if(sk, skb);
dst = af_ops->route_req(sk, skb, &fl, req);
if (!dst)
goto drop_and_free;
if (tmp_opt.tstamp_ok)
tcp_rsk(req)->ts_off = af_ops->init_ts_off(net, skb);
inet_request_bound_dev_if는 넘기도록 하겠습니다.
이제 SYN|ACK을 보내기 위해서 dst_entry를 알아내야 합니다. af_ops는 tcp_request_sock_ipv4_ops였고, 이 함수에서 route_req는 tcp_v4_route_req가 연결되어 있습니다.
5-6. tcp_v4_route_req
// net/ipv4/tcp_ipv4.c/tcp_v4_route_req() :1481
static struct dst_entry *tcp_v4_route_req(const struct sock *sk,
struct sk_buff *skb,
struct flowi *fl,
struct request_sock *req)
{
tcp_v4_init_req(req, sk, skb);
if (security_inet_conn_request(sk, skb, req))
return NULL;
return inet_csk_route_req(sk, &fl->u.ip4, req);
}
5-6-1. tcp_v4_init_req
// net/ipv4/tcp_ipv4.c/tcp_vr_init_req() :1469
static void tcp_v4_init_req(struct request_sock *req,
const struct sock *sk_listener,
struct sk_buff *skb)
{
struct inet_request_sock *ireq = inet_rsk(req);
struct net *net = sock_net(sk_listener);
sk_rcv_saddr_set(req_to_sk(req), ip_hdr(skb)->daddr);
sk_daddr_set(req_to_sk(req), ip_hdr(skb)->saddr);
RCU_INIT_POINTER(ireq->ireq_opt, tcp_v4_save_options(net, skb));
}
해당 함수는 request sock의 source address를 설정합니다. 그 주소는 skb의 목적지 주소에서 가져옵니다.
sk_rcv_saddr_set 함수와 sk_daddr_set 함수는 다음과 같이 생겼습니다.
// include/net/inet_hashtables.h/sk_rcv_saddr_set() :419
static inline void sk_rcv_saddr_set(struct sock *sk, __be32 addr)
{
sk->sk_rcv_saddr = addr; /* alias of inet_rcv_saddr */
#if IS_ENABLED(CONFIG_IPV6)
ipv6_addr_set_v4mapped(addr, &sk->sk_v6_rcv_saddr);
#endif
}
// include/net/inet_hashtables.h/sk_daddr_set() :411
static inline void sk_daddr_set(struct sock *sk, __be32 addr)
{
sk->sk_daddr = addr; /* alias of inet_daddr */
#if IS_ENABLED(CONFIG_IPV6)
ipv6_addr_set_v4mapped(addr, &sk->sk_v6_daddr);
#endif
}
tcp_v4_save_options는 ip layer option을 처리합니다. 따라서 현재의 관심사가 아니므로 넘어가겠습니다.
5-6-2. inet_csk_route_req
inet_csk_route_req는 라우팅 테이블을 확인해서 목적지 대상을 가져옵니다. dst_entry는 다음과 같이 생겼습니다.
// include/net/dst.h :25
struct dst_entry {
struct net_device *dev;
struct dst_ops *ops;
unsigned long _metrics;
unsigned long expires;
#ifdef CONFIG_XFRM
struct xfrm_state *xfrm;
#else
void *__pad1;
#endif
int (*input)(struct sk_buff *);
int (*output)(struct net *net, struct sock *sk, struct sk_buff *skb);
unsigned short flags;
#define DST_NOXFRM 0x0002
#define DST_NOPOLICY 0x0004
#define DST_NOCOUNT 0x0008
#define DST_FAKE_RTABLE 0x0010
#define DST_XFRM_TUNNEL 0x0020
#define DST_XFRM_QUEUE 0x0040
#define DST_METADATA 0x0080
/* A non-zero value of dst->obsolete forces by-hand validation
* of the route entry. Positive values are set by the generic
* dst layer to indicate that the entry has been forcefully
* destroyed.
*
* Negative values are used by the implementation layer code to
* force invocation of the dst_ops->check() method.
*/
short obsolete;
#define DST_OBSOLETE_NONE 0
#define DST_OBSOLETE_DEAD 2
#define DST_OBSOLETE_FORCE_CHK -1
#define DST_OBSOLETE_KILL -2
unsigned short header_len; /* more space at head required */
unsigned short trailer_len; /* space to reserve at tail */
/*
* __refcnt wants to be on a different cache line from
* input/output/ops or performance tanks badly
*/
#ifdef CONFIG_64BIT
atomic_t __refcnt; /* 64-bit offset 64 */
#endif
int __use;
unsigned long lastuse;
struct lwtunnel_state *lwtstate;
struct rcu_head rcu_head;
short error;
short __pad;
__u32 tclassid;
#ifndef CONFIG_64BIT
atomic_t __refcnt; /* 32-bit offset 64 */
#endif
};
L3와 라우팅 테이블은 다음에 살펴보도록 하겠습니다.
어쨌든 af_ops->route_req를 통해서 SYN | ACK을 보낼 경로를 설정합니다.
중간점검
현재까지의 request sock 값들이 우리가 예상한 값들과 같은지 한 번 출력해봅시다. 다음처럼 6865줄 옆에 우리가 만들 함수를 호출해줍시다.
dst = af_ops->route_req(sk, skb, &fl, req); byeo_print_reqsk_data(req);
void byeo_print_reqsk_data(struct request_sock *req)
{
struct sock_common* rsk_common = &req_to_sk(req)->__sk_common;
struct inet_request_sock *ireq = inet_rsk(req);
struct tcp_request_sock *tcpreq = tcp_rsk(req);
printk("[byeo:req:sk_common] tx_queue_mapping %d, refcnt %p, cookie %ld, rcvwnd %d, state %d, net %p, family %d\n", rsk_common->skc_tx_queue_mapping, rsk_common->skc_refcnt.refs, rsk_common->skc_cookie, rsk_common->skc_rcv_wnd, rsk_common->skc_state, rsk_common->skc_net, rsk_common->skc_family);
printk("[byeo:req:sk_common] dport %d, num %d, rcv_saddr %d, daddr %d\n", rsk_common->skc_dport, rsk_common->skc_num, rsk_common->skc_rcv_saddr, rsk_common->skc_daddr);
printk("[byeo:req:req] mss %d, num_retrans %d, syncookie %d, num_timeout %d, ts_recent %d, rsk_timer %p, saved_syn %p\n", req->mss, req->num_retrans, req->syncookie, req->num_timeout, req->ts_recent, req->rsk_timer, req->saved_syn);
printk("[byeo:req:ireq] ireq_opt %p, sack_ok %d, wscale_ok %d, acked %d, ecn_ok %d, ir_mark %d\n", ireq->ireq_opt, ireq->sack_ok, ireq->wscale_ok, ireq->acked, ireq->ecn_ok, ireq->ir_mark);
printk("[byeo:req:tcpreq] ts_off %d, rcv_isn %d, rcv_nxt %d, snt_synack %lld, last_oow_ack_time %d\n", tcpreq->ts_off, tcpreq->rcv_isn, tcpreq->rcv_nxt, tcpreq->snt_synack, tcpreq->last_oow_ack_time);
}

rcv_saddr: 335544330 = 0x14 00 00 0A = 20.0.0.10 -> ntoh -> 10.0.0.20
daddr: 16777226 = 0x01 00 00 0A = 1.0.0.10 -> ntoh -> 10.0.0.1
- https://stackoverflow.com/questions/8312880/how-the-kernel-continues-with-the-three-way-handshake-after-it-sets-the-state-to [본문으로]
- https://arthurchiao.art/blog/tcp-listen-a-tale-of-two-queues/#41-server-received-a-syn-3whs-progress-13 [본문으로]
- https://www.emqx.com/en/blog/emqx-performance-tuning-tcp-syn-queue-and-accept-queue [본문으로]
'프로그래밍 (Programming) > 네트워크 스택' 카테고리의 다른 글
| TCP SYN_RECV state의 ACK 처리 1 (0) | 2024.06.02 |
|---|---|
| Listen socket의 TCP SYN 처리 2 (0) | 2024.05.31 |
| ftrace 사용법 (0) | 2024.05.23 |
| accept system call 3 (inet_accept) (0) | 2024.05.19 |
| [Linux Kernel] Blocking I/O (0) | 2024.05.17 |


