
- Today
- Total
Byeo
Understanding Host Network Stack Overheads 3 / 네트워크 스택 비용의 이해 3 본문
Understanding Host Network Stack Overheads 3 / 네트워크 스택 비용의 이해 3
BKlee 2023. 7. 28. 22:48해당 게시글은 Sigcomm '21 Understanding Host Network Stack Overheads를 번역하여 정리한 글입니다.
이전 게시글
Traffic Pattern 외 고려 요소
논문은 이제 traffic pattern 외에도 TCP/IP 구현, Host의 다른 hardware 등을 고려하여 정리하였다. 목록 순서는 다음과 같다.
(f) In-network congestion (내부 네트워크 혼잡)
(g) Flow size의 영향
(h) DCA의 영향
(i) IOMMU의 영향
(j) Congestion control (프로토콜의 혼잡 제어 구현)의 영향
(f) In-network Congestion
In-network congestion이란 end-host가 아닌 swtich나 router 등 네트워크 packet을 전달해주는 내부 장비에서 처리량을 소화하지 못해 drop이 발생하는 상황을 의미한다. 저자는 sender와 receiver 사이에 switch를 하나 두고, single flow가 흐르는 상황 하에서 switch의 drop rate를 0부터 0.015까지 늘려가며 실험하였다.

Figure 9(a)는 CPU core당 대역폭 효율을 나타낸다. Drop rate가 0.015로 증가하면 24%의 효율이 감소하는 것을 확인할 수 있었다. 특별한 점으로, drop rate가 0일 때보다 1.5e-4일 때 효율이 미약하게 증가한 결과를 볼 수 있다. 이는 packet drop으로 인해 throughput이 감소하였고, receiver의 L3 cache miss rate가 이에 따라 미약하게 감소하여 성능이 상승한 것으로 저자는 해석하였다.
Figure 9(b)는 CPU 사용량을 나타내는데, drop rate가 높을수록 Rx-side의 CPU 사용량이 낮아지는 것을 확인하라 수 있다. 특징으로 drop rate가 증가할수록 sender와 receiver의 CPU 사용량이 비슷해지는 것을 확인할 수 있다.
Figure 9(c)와 9(d)는 각각 sender와 receiver의 CPU 사용량을 분석한 그래프이다. Drop rate가 높아질수록 TCP 처리나 netdevice의 비율이 증가하는 것을 관측했고, 이에 따라 상대적으로 data copy의 비중은 감소하는 결과를 낳았다.
Drop rate의 증가는 (1) Rx가 TCP가 ACK를 처리하는 비용, (2) Tx가 packet retransmission 하는 비용의 증가를 가져온다. Rx-side에서는 drop rate를 0에서 0.015로 증가시켰을 때, ACK를 생성하고 전송하는 비용이 4.87배 (1.52% → 7.4%) 증가했다고 한다. Tx-side에서는 drop rate를 0에서 0.15로 증가시켰을 때, ACK를 처리하는 비용이 1.45배 (5.79% → 8.41%) 증가했으며 retransmission을 위해 CPU 사용량이 1.34% 추가로 증가했다고 한다.
Packet drop으로 인해 retransmission이 발생할 경우 Tx-side의 부담이 증가한다. Tx-side에서 위에서 언급한 ACK 처리, retransmission 외에도 congestion control 등 다양한 요소가 figure 9(b)의 경향 (Tx-side CPU usage ≒ Rx-side CPU usage)을 만든 것으로 저자는 해석하고 있다.
(g) Flow size의 영향
Linux network stack의 flow size영향을 보기 위하여 저자는 short flow로서 ping-pong style RPC workload를 채택했다. RPC의 메시지 크기를 4KB에서 64KB로 늘려가면서 테스트 했으며, Rx-side에 CPU core 병목을 만들기 위하여 incast 형태로 16개의 flows의 트래픽이 있는 환경을 가정했다. 더불어서 single flow와 long flow가 섞여있을 때도 해당 환경에서 실험했다고 한다.

Figure 10(a)는 CPU core당 대역폭 효율을 나타낸다. 예상대로 flow size가 클 수록 효율이 상승한다. Figure 10(b)는 CPU 사용량을 분석한 결과를 나타낸다. 작은 flow size의 RPC에서는 data copy가 적은 비중을 차지하는 반면, 작은 size로 인한 낮은 GRO 효율로 인해 TCP/IP 처리 비용이 증가하였다. 마찬가지로 ping-pong RPC를 사용함으로써 idle 상태가 증가하였고, 이는 scheduling 비용이 증가하는 결과를 가져왔다.
Figure 10(c)는 CPU core당 대역폭 효율과 cache miss rate의 상관관계를 나타낸다. Long flow에서는 NIC-remote NUMA의 경우 DCA를 활용할 수 없어 cache miss rate가 높았고, 그에 따라 전체적인 효율도 좋지 못했다. 하지만 short flow에서는 낮은 data copy 비중으로 인해 DCA의 영향력이 감소했고, NIC-local NUMA와 NIC-remote NUMA의 효율 차이가 거의 없는 결과를 보였다. 다만, DCA의 이득은 적었지만 application core와 IRQ core를 같은 곳에 위치시키는 aRFS의 효율은 여전히 좋았다.
위 관찰점을 종합하면 다음 교훈을 얻을 수 있다.: long flow는 NIC-local NUMA에 위치하는 것이 중요한 반면, short flow는 NIC-remote NUMA에 위치해도 상관이 없다. 단, 해당 교훈은 4KB RPC에서는 유효하지만 16KB RPC만 되더라도 data copy가 바로 주된 비용이 되는 점을 감안해야 한다.

Figure 11 (a)는 long flow를 처리하고 있는 CPU core에서 short flow를 같이 실행하면 CPU core당 대역폭 효율이 어떻게 되는지 실험한 결과이다. Long flow를 처리중인 CPU core에서 short flow를 실행하지 않으면 42 Gbps (single flow case와 동일)의 성능을 보이지만, 16개의 short flow를 같은 CPU core에서 처리하는 순간 그 효율이 43% 저하된다.
Long flow와 short flow는 각각 독립된 환경에서 실행하면 42Gbps와 6.15Gbps의 성능을 보인다. 하지만 이들을 같은 CPU core에 섞는 순간 20Gbps와 2.6Gbps로 성능이 저하(각각 48%, 42%)된다.
(h) DCA 영향
지금까지 실험 결과는 DCA를 활용했을 때의 결과이다. DCA를 끄면 어떻게 될까?
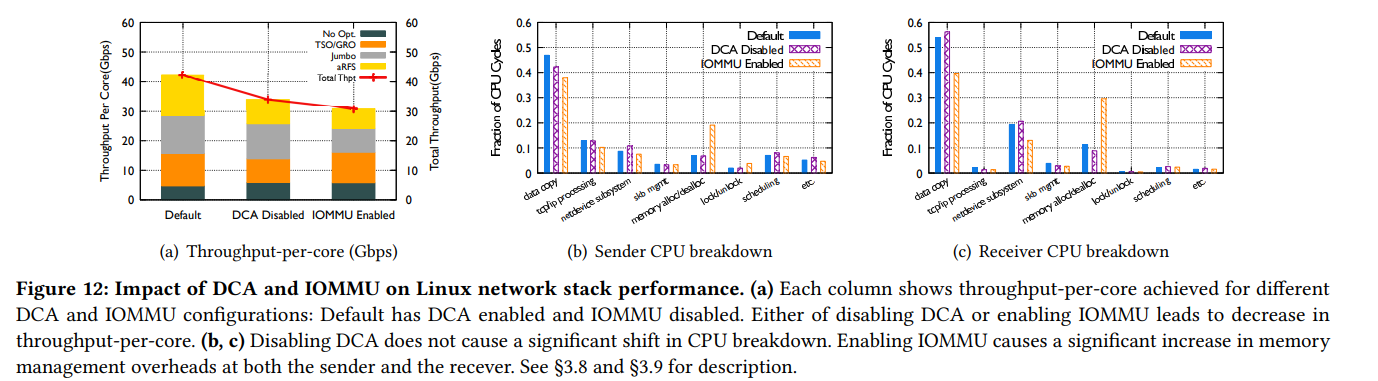
Figure 12(a)는 DCA 여부에 따라 CPU core당 대역폭 성능을 보여준다. DCA를 사용하지 않으면 약 19%의 효율이 저하되었으며, 특히 aRFS의 효율이 50% 저하되었다. 이는 aRFS를 사용하여 IRQ context와 application context의 CPU를 맞춰주더라도, DCA를 사용하지 않으면 DRAM으로부터 data를 불러와야 하므로 cache miss rate가 증가하기 때문이다.Figure 12(b)와 12(c)는 DCA를 disable하더라도 병목의 변화는 없음을 보여주고 있다. (여전히 Rx가 병목)
(i) IOMMU 영향
IOMMU는 가상화 환경에서 빠른 IO를 제공하기 위하여 사용된다. 또는 가상화 환경이 아니더라도 메모리 보호를 가져다 준다는 이점이 있다. 장치는 virtual address를 이용해 DMA 요청을 수행하고, 중간의 IOMMU가 메모리 위반 여부를 체크한 뒤 physical address로 변환해준다. 저자는 지금까지의 모든 실험에서 IOMMU를 사용하지 않았다.
IOMMU는 중간에 메모리 관리 비용이 추가되기 때문에 성능이 저하된다. Figure 12(a)에서 볼 수 있듯이 기존과 비교하여 26%의 효율 저하를 보이며, figure 12(b)와 12(c)에서 보이듯 메모리 관리 비용이 상당히 증가한다.
메모리 관리 비용의 증가 원인으로는 다음과 같이 2가지 추가 작업을 필요로 하기 때문이다. (1) NIC driver가 DMA를 위한 공간을 할당할 때, 장비의 IOMMU pagetable에도 해당 정보를 추가해야 하고, (2) DMA가 끝나면 driver는 이 page를 또 다시 해제해야 하기 때문.
(j) Congestion Control 영향
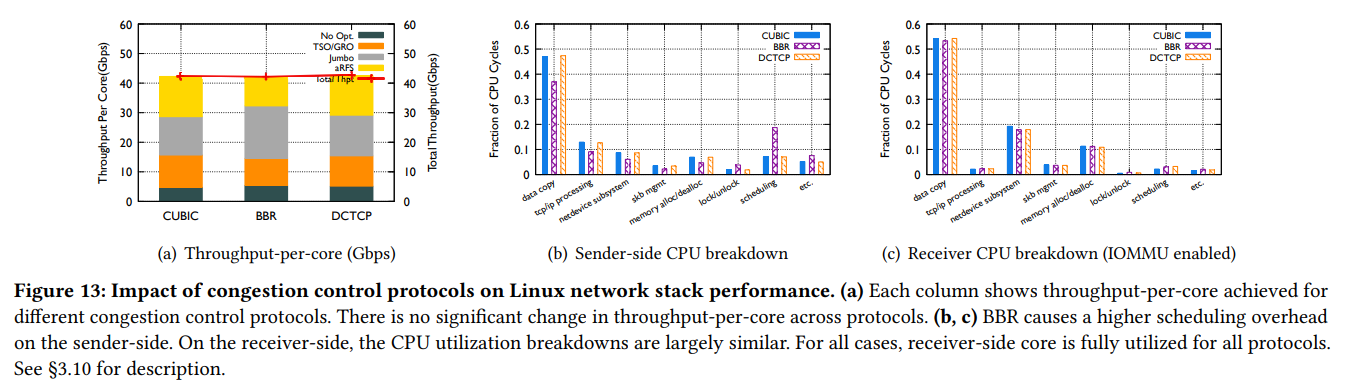
현재까지 모든 실험은 TCP CUBIC (Linux 기본 congestion control algorithm)을 사용하여 진행하였다. 저자는 BBR, DCTCP를 추가로 실험하였으며 figure 13(a)를 보면 성능에는 별 차이가 없는 것을 확인할 수 있다. 이는, 보통의 병목 원인은 Rx-side지만 비교대상 congestion control 알고리즘들은 sender 중심이기 때문이다. Figure 13(c)의 Rx-side CPU 분석 그래프의 별 차이 없는 결과가 이를 뒷받침한다.
시사점
Zero-copy Mechanism
그 동안의 결과들을 살펴보면 long flow의 경우 많은 CPU cycle이 data copy에 쓰이는 것을 확인할 수 있다. 이에 따라 Zero-copy 방법론의 필요성이 대두되고 있다. Tx-side에는 MSG_ZEROCOPY (kernel 4.14부터 포함)를 제공하고 있다. 이는 send 시스템 콜이 호출될 때 application buffer를 pinning 하고 NIC이 바로 DMA를 해감으로써 zero-copy를 달성한다. Rx-side에서는 TCP socket에 mmap 기법을 활용한 zero-copy (kernel 4.18부터 포함) 기능을 제공한다. 해당 기법은 kernel로부터 DMA를 위한 physical address였던 공간에 대해 application이 mmaped virtual address를 제공받는 방식이다.
하지만 Tx-side 기법과 Rx-side 기법은 모두 application code를 수정해야 한다. 특히 Rx-side의 경우 메모리 관리기법부터 application code까지 많은 부분을 수정해야 한다는 문제가 있다.
AF_XDP (Linux eXpress Data Path socket)을 이용한 zero-copy (kernel 4.18부터 포함) 방법도 있지만, 이 역시 많은 부분을 고쳐야 한다. 최종적으로, application code의 수정이 필요 없는 zero-copy 방법론은 흥미로운 탐구가 될 것이라고 저자는 제안하였다.
CPU 효율적인 TCP design
그 동안 TCP design은 latency 최소화, 대역폭 증가 등을 목적으로 주로 congestion / flow control 알고리즘에 치우쳐져 있었다. 지금까지는 in-network가 주 병목 원인이었기에 그랬지만, 논문에서 다뤘듯 이제는 end-host가 병목이 되는 케이스가 많아졌다. 앞으로는 다양한 host resources (Cache buffer, DCA 여부 등)을 같이 고려하는 TCP design이 필요할 것이다.
Host stack 재구성의 필요성
(1) 현재의 네트워크 스택 디자인은 socket 생성시에 결정되는 많은 요인들에 집중하여 packet processing pipeline이 구성되어 있다. 하지만 논문에서 보여준 short flow와 long flow가 섞인 사례와 같이 runtime에 어떻게 동작하는지 여부는 고려하지 않는다. 즉, application이 어떻게 돌아가는지에는 관심이 없다 (application-agnostic). 이제는 host resource가 병목이 되는 만큼, 자원을 더 효율적으로 배분 및 확장할 수 있는 구성과 application의 특성을 파악할 줄 아는 네트워크 스택 디자인이 필요하다.
(2) CPU scheduler와 네트워크 스택을 함께 구성할 필요가 있다. 현재까지 CPU scheduler와 네트워크 스택은 완전 별도로 구성 및 발전해왔다. 하지만 application이 동시에 많은 CPU core에서 돌아가는 구조에서는 CPU scheduler의 CPU cycle 사용 비중이 무시할 수 없음을 보였다. 이에 저자는 scheduler를 별도로 생각할 수 있는지 다시 생각해봐야 할 것이라고 이야기 한다.
정리 후기
- 글로 한 번 쓰는게 기억에 오래 가는 듯 해요. 시간이 나면 종종 석사때 읽었던 논문이나 최근 나오는 관련 분야 논문 요약을 해봐야겠습니다.
- 처음에는 한국어로 모두 쓰려다가 어색해서 점점 영어단어를 쓰게 된 것 같습니다. 양해 부탁드립니다..
- 내용 개선점, 피드백, 비문 등 다양한 부분에서 댓글 남겨주시면 감사하겠습니다~


