
- Today
- Total
Byeo
Understanding Host Network Stack Overheads 2 / 네트워크 스택 비용의 이해 2 본문
Understanding Host Network Stack Overheads 2 / 네트워크 스택 비용의 이해 2
BKlee 2023. 7. 19. 23:51해당 게시글은 Sigcomm '21 Understanding Host Network Stack Overheads를 번역하여 정리한 글입니다.
이전 게시글
네트워크 스택의 비용에 관한 이해 1
Understanding Host Network Stack Overheads 해당 논문은 Sigcomm 21년에 공개된 논문으로, 현존 NIC이 제공하는 기능들, 커널의 네트워크 스택의 작업, 그리고 CPU 사이에서의 연관관계를 잘 정리하였다. [링크]
byeo.tistory.com
Type of Traffic Patterns

논문은 traffic pattern의 종류를 위 그림처럼 5가지로 구분하였다.
(a) single: 1개의 sender와 receiver application이 각자 1개의 CPU core에서 동작
(b) one-to-one: 다수의 sender와 receiver applications이 개별 CPU core에서 동작
(c) incast: 다수의 sender applications는 개별 CPU core에서, 다수의 receiver applications응 1개의 CPU core에서 동작
(d) outcast: 다수의 sender applications는 1개의 CPU core에서, 다수의 receiver applications는 개별 CPU core에서 동작
(e) all-to-all: 다수의 sender와 receiver applications가 여러 CPU core에서 분산하여 동작
(a) Single Flow
앞 게시글에서 언급한 내용대로, 예전에는 application이 동작하는 end-host는 single CPU만으로도 높지 않았던 link bandwidth를 채울 수 있어서 문제가 없었다. 오히려 이 당시에는 스위치, 라우터 등의 중간 영역이 병목으로서 동작했었다. 하지만 네트워크 대역폭은 크게 증가함에 따라 이 이야기는 성립하지 않게 되었다.
저자는 두 서버가 NIC-local NUMA의 CPU core에서 application을 실행하는 환경에서 실험하였다. ※ Rx-side의 IRQ는 실제로 3가지 케이스가 가능한데, (1) application과 동일한 CPU core (aRFS가 활성화 되어있으면 보장 가능), (2) application과 동일한 NUMA node, (3) 전혀 다른 NUMA node로 나뉜다. 저자는 aRFS를 사용하지 않는 상황의 경우 worst-case인 '3번' 상황을 가정했다.
추가로 LRO는 real-world에 아직 잘 사용되지 않는 기법이고, 그에 따라 GRO를 사용하여 측정하였다.
Figure 3(a)는 CPU core당 대역폭을 나타낸다. 모든 기능과 최적화를 사용해도, 1개의 CPU core로는 42 Gbps만 달성할 수 있다. Jumbo frame과 TSO/GRO는 skb의 개수를 줄일 수 있다는 점 (skb당 더 많은 payload를 보유할 수 있으므로)에서 성능 향상에 긍정적인 영향을 주었다. DCA와 더불어 aRFS를 사용하는 경우에는 L3 cache에 바로 데이터를 적을 수 있으므로 (NIC-local NUMA 이므로), 성능 향상이 더 가능했다.
Figure 3(b)는 CPU 사용량을 나타낸다. 이 논문에서는 네트워크 스택의 높은 CPU 사용량을 지적하고 있으므로 그래프가 낮을수록 좋다. Rx-side가 Tx-side보다 CPU 사용량이 현저히 높은데, 저자는 그 이유로 다음과 같이 2가지를 뽑는다.
(1) Remote NUMA에 의한 비효율적인 복사. 먼저, aRFS가 활성화 되지 않은 경우, NIC remote에 data를 쓰고 (3번 상황 가정) 이를 다시 application local CPU로 복사해야 한다. Remote NUMA간의 데이터 복사는 local NUMA보다 성능이 떨어지기에 byte당 비용이 증가하게 된다. Tx-side는 L3 cache에 application data가 존재할 것 (warm)이기에 문제되지 않는다.
(2) skb allocation 비용의 차이. Tx-side는 하드웨어 기반의 TSO를 사용하여 더 많은 데이터를 포함할 수 있는 skb를 생성하는 반면, Rx-side는 소프트웨어 기반의 GRO를 사용하기에 MTU-sized skb를 device driver에서 생성한 뒤 합쳐야 한다.
Figure 3(c)와 3(d)는 각각의 상황에서 CPU가 어디에 쓰이는지를 나타낸다. 최적화가 사용되지 않으면 hardware의 도움도 없고 프로토콜도 skb마다 처리를 해줘야 하므로 TCP/IP processing의 비용이 가장 크다. Rx에서 aRFS가 사용되지 않는 경우, application thread와 interrupt thread가 같은 socket을 다루기에 lock 비용을 필요로 한다.
Tx-side에서 TSO와 jumbo frame을 사용하면 TCP/IP에서 처리해야 하는 작업(segmentation)과 skb 개수가 줄어든다.
Rx-side에서 GRO를 사용하면 TCP/IP 레이어에서 처리해야 할 skb개수가 줄어드므로 마찬가지. 단, GRO를 수행해야 하는 netdevice subsystem의 비율이 증가함을 확인할 수 있다. 이 또한 jumbo frame을 사용하면 다시 netdevice subsystem의 비용을 66% 줄일 수 있다. GRO, jumbo frame을 모두 사용하면 최종적으로 대역폭이 증가하고, 주요 비용은 data copy로 옮겨지게 된다.
마지막으로 aRFS를 사용하면 application thread와 IRQ thread를 같은 CPU core에서 수행할 수 있고, cache와 NUMA locality를 끌어올릴 수 있다. 이는 다음과 같은 효과를 얻는다: (1) 두 thread가 같은 CPU core에서 돎으로 DCA가 가능하고, copy 비용을 줄일 수 있다. (2) skb 할당과 해제가 같은 CPU core에서 이뤄지므로 해제의 비용이 감소한다. (NUMA-local memory에 있는 page free비용이 훨씬 낮다고 한다.)
Figure 3(e)는 대역폭과 L3 cache miss 비율을 나타낸다. NIC Rx descriptor의 개수와 TCP Rx buffer size를 늘려가면서 실험했을 때 miss rate가 증가하는 모습을 보였다. 이는 (1) BDP가 cache size를 초과하면서, (2) Cache 사용이 최적이 아님을 이유로 뽑았다.
(1) TCP Rx buffer size를 크게 잡을 경우 Rx buffer는 BDP만큼의 데이터를 수용할할 것이고, 이는 host CPU core가 병목이 되는 경우 latency를 상당히 증가시킨다. 이와 더불어 IRQ thread와 application thread의 스케줄링 delay까지 추가되어, 저자는 실제로 패킷이 도착했을 때 앞에 이미 많은 패킷이 처리되지 않은 상황을 관측했다고 한다.
Figure 3(f)는 실제로 저자가 NAPI polling과정 중에 skb를 생성할 때부터 application buffer로 data copy를 시작할 때 사이의 소요 시간을 TCP Rx buffer size에 따라 나타낸 그래프다. TCP Rx buffer size가 1600KB를 넘어갈 때 delay가 급증하였다. 이렇게 delay가 증가하고 host가 packet들을 전부 처리를 하지 못하는 상황에서도 NIC은 계속 L3 cache로 DMA할 것이다. 하지만 DCA size는 제한되어 있기에 이를 초과하는 경우 cache eviction이 발생시킬 것이고, 결국 cache miss가 증가하게 된다.
(2) Rx descriptor의 개수가 많은 경우, NIC DMA를 위해 필요한 memory address의 개수도 많이 필요하다. 이 때, BDP의 값이 작을지라도 DCA가 기존의 데이터를 eviction할 가능성이 높아지게 된다. 결국 DCA와 L3 cache를 이용한 networking이 최적이 아닌 결과를 가져오게 되는 것이다. (Linux kernel이 DCA의 효과를 고려하지 않는다고 한다.)
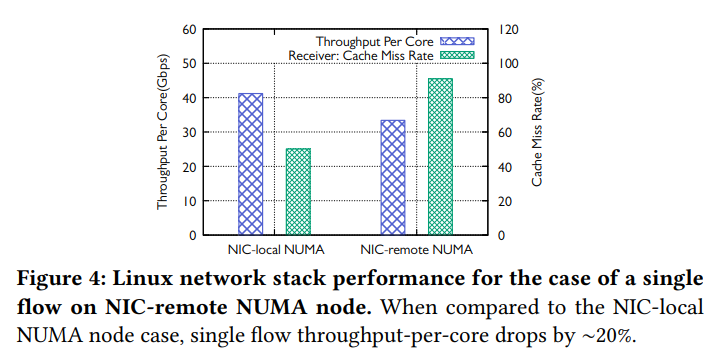
Figure 4는 aRFS를 사용하더라도 NIC과 application core가 같은 NUMA에 있는지, 혹은 다른 NUMA에 있는지에 따라 성능이 어떻게 변화하는지 나타낸 그래프이다. aRFS를 사용하더라도 application core를 위한 L3 cache NUMA와 NIC NUMA가 다른 경우 DCA가 데이터를 곧 바로 넣어줄 수 없기에 대역폭이 20% 하락하게 되는 것이다.
Glossary
- Payload: packet에서 application 데이터를 포함한 영역
- NUMA: Non-Uniform Memory Access. CPU core와 Memory의 위치에 따라 Memory access 비용이 다르다. [위키]
(b) One-to-one
One-to-one traffic pattern은 Tx-side의 각 CPU core가 Rx-side의 CPU에 1:1 매핑된 것이다. 저자는 CPU core 개수를 1개부터 24개까지 늘려가면서 실험하였다. 이 패턴은 다수의 CPU core를 사용하므로 (1) network 대역폭이 병목이 되고, (2) NIC-local NUMA flow와 NIC-remote NUMA flow가 혼재하게 된다.
이 실험에서는 NUMA node가 6개이며, single flow와 마찬가지로 aRFS가 활성화되지 않으면 3번 상황 (application CPU core와 다른 NUMA node에서 IRQ를 처리)을 가정한다.
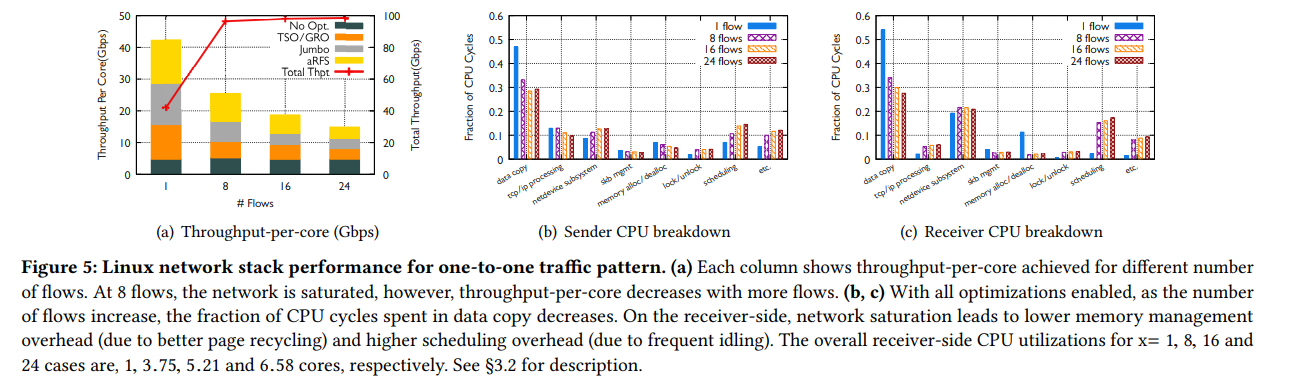
Figure 5(a)는 CPU core당 대역폭 효율을 나타낸다. Flow의 개수가 늘어날 수록, 즉 사용되는 CPU core의 수가 늘어날 수록 CPU core당 대역폭 효율이 저하되어 최대 64%까지 낮은 결과를 보인다. 그 이유는 flow의 개수가 많을수록 optimization의 효과가 약해지기 때문.
GRO의 효과가 flow가 많아질수록 낮아지는데, 이는 다수의 flow가 서로 간섭함으로 인해 GRO (packet aggregation)의 기회를 잃게 만들기 때문이다.
aRFS는 24-flow에서 그 효율이 75%나 감소한다. 이는 동일 NUMA에 있는 CPU core가 L3 cache를 공유하기에 이를 효율적으로 사용하지 못한다는 점, 그리고 remote NUMA는 DCA를 활용할 수 없다는 점이 원인으로 꼽힌다.
Figure 5(b)와 5(c)는 각각 Tx-side와 Rx-side의 CPU 사용량이 어떻게 구성되어 있는지 나타낸다. 먼저, Figure 5(a)에 보이는 것 처럼 flow의 개수가 8개가 되면 network 대역폭을 채우게 된다. 이에 따라 CPU를 주로 사용하는 항목이 바뀌게 되는데, 눈에 띄는 것은 다수의 flow에서 shceduling 비용의 증가와 memory alloc/dealloc 비용의 감소이다.
(1) scheduling 비용의 증가. 8개 이상의 flow에서 network가 병목이 되었고 이를 다시 말하면 CPU core가 packet을 제때 처리하지 못하게 되어 idle한 상태가 되는 시간이 생기게 된 다는 의미이다. CPU core가 주기적으로 sleep상태에 빠지며, 데이터의 전송이 가능해지거나 도착한 packet이 있을 경우 wake되어 결과적으로 scheduling 비용은 증가하는 결과를 보였다.
(2) memory alloc/dealloc 비용의 감소. memory alloc/dealloc의 비용은 per-core pageset 기법이 영향을 주었다고 저자는 설명하였다. per-core pageset은 CPU core별로 할당가능한 page를 별도로 관리하며, 필요할 때 여기서 곧바로 제공한다. 만약 per-core pageset의 공간이 부족해지면 조금 더 비용이 큰 global free-list에서 제공한다. 따라서 single flow 일 때보다 다수의 flow traffic pattern에서 global free-list를 접근할 일이 더 줄어들 것이므로 (개별 CPU core의 pageset에서 제공 받을 일이 더 많으므로) 비용이 감소하게 되는 것이다.
(c) Incast
Incast는 sender에 다수의 CPU core를 사용하고 1개의 receiver CPU core로 traffic을 보내는 패턴이다. 저자는 sender의 CPU core를 1개부터 24개까지 늘려가며 측정하였다.
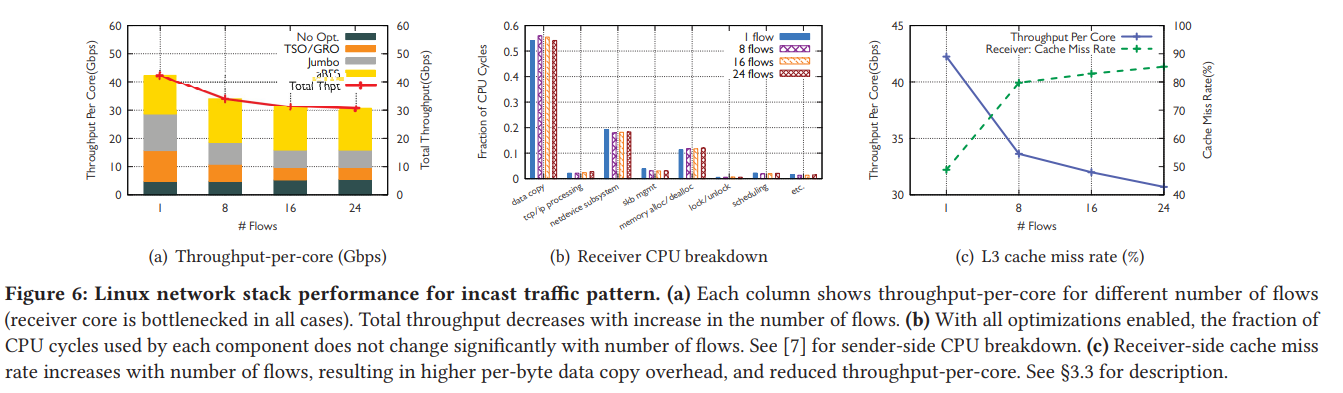
Figure 6(a) 는 CPU core당 대역폭 효율을 나타내며, 8개의 flow에서는 효율이 19%만큼 저하됐다. Figure 6(b)는 Rx-side CPU 사용량 분석을, figure 6(c)는 L3 cache miss rate를 나타낸다. 6(c)를 보면 flow가 증가할 수록 Rx-side의 L3 cache miss rate가 48% (1 flow)에서 88% (24 flows)로 증가하는 것을 확인할 수 있다. 이는 Rx-side에서 같은 CPU core를 사용하면서 모든 flow가 L3 cache를 공유하게 되었고, 그 결과 L3가 모든 data를 수용할 수 없게 되었기 때문이다.
또한, Rx-side의 1개 core에서 여러 application이 동시에 수행됨에 따라 CPU scheduling의 비효율이 발생하는 점도 고려해야 한다.
(d) Outcast
Outcast는 1개의 CPU core 위에서 실행되는 다수의 application들이 다수의 receiver core로 traffic을 보내는 패턴이다. 저자는 receiver CPU core를 1개부터 24개까지 늘려가며 측정하였다.
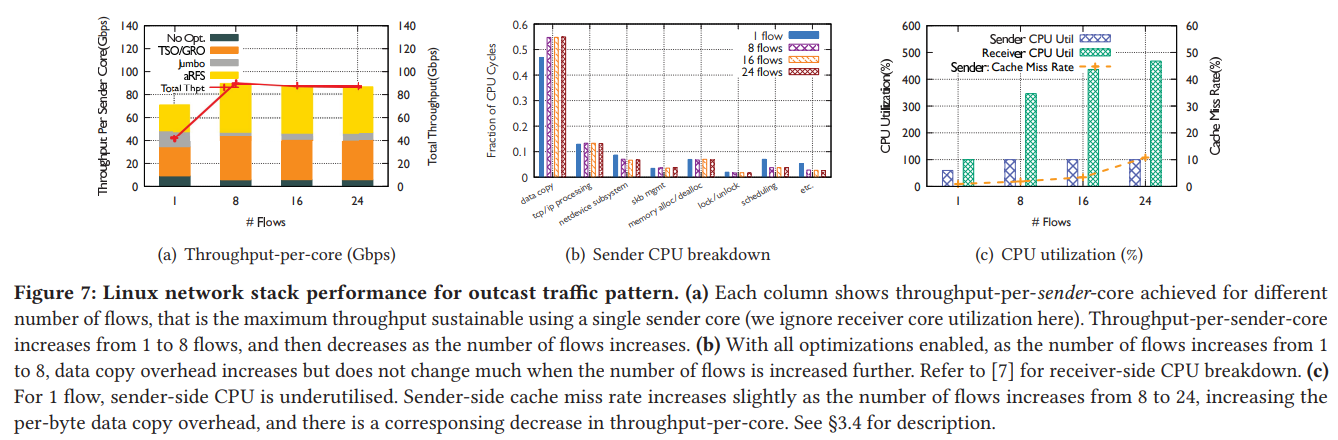
Figure 7(a)는 sender-side의 CPU core당 대역폭 효율을 나타낸다. Figure 6(a)와 비교하면, Rx-side보다 Tx-side에서 CPU core당 효율이 2.1x 높은 것을 확인할 수 있다. 이는 현대 Linux kernel이 Tx-side를 Rx-side보다 CPU 효율적으로 구현했음을 보여준다. Figure 7(a)를 보면 flow가 많을 때 TSO의 효율이 좋음을 확인할 수 있다. (이와 반대로 figure 6(a)의 GRO는 효율이 감소하는 것을 확인할 수 있다.) 그 이유로는 (1) CPU로 처리하는 GRO와는 달리 TSO는 NIC hardware가 처리를 해주는 것이고, (2) application이 항상 skbs에 64KB단위로 데이터를 넣기 때문이다. (?)
또한, aRFS도 상당한 기여를 하고 있음을 알 수 있다. 이는 Rx-side에서 core를 여러개 사용하기 때문에 application core에 직접 배분하는 효과가 크기 때문이다. 이 traffic pattern에서 가장 큰 비용은 figure 7(b)에 나타난 것 처럼 data copy이다.
(e) All-to-all
이 traffic pattern은 x개의 CPU core 위에서 실행되는 sender application이 다른 서버 x개의 CPU core위에서 실행되는 receive application에게 데이터를 보내는 pattern이다. x는 1부터 24로 늘려가며 실험하였다.
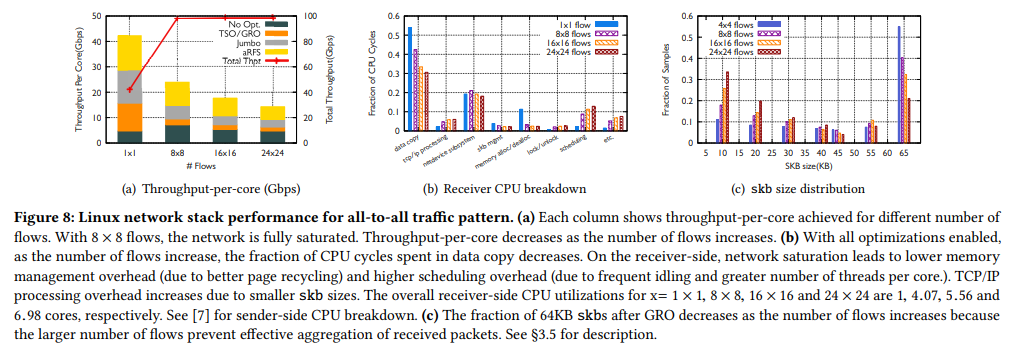
저자는 실험에 쓰이는 NIC의 IRQ mapping 개수가 576개 (24x24)를 수용할 수 없기에 모든 실험에서 이를 사용하지 않았다고 한다. 그럼에도 불구하고, flow 개수가 많기 때문에 매 실행마다 나름 일관된 결과가 나왔다고 한다.
Figure 8(a)는 CPU core당 대역폭 효율이다. 24x24 flows에서는 single flow일 때보다 67% 낮은 효율을 보였다. 이는 NIC-remote NUMA가 함께 존재함에 따라 aRFS 효율이 저하되었고 cache miss rate도 높아졌기 때문이다. (Incast와 유사)
이 시나리오는 one-to-one처럼 network 대역폭이 병목이되고, 그에 따라 모든 flow들이 최대 가능 대역폭보다 상당히 낮은 성능을 동등하게 공유하게 된다. (50 Gbps를 576 flows가 나눈다고 생각해보자) 이는 Rx-side에서 packet을 빠르게 수신할 수 없기 때문에, 수신한 packet들을 최대한 모아 하나의 skb로 만들어주는 GRO 기법의 효율을 저하시킨다. 즉, skb 개수가 증가하므로 protocol processing 관련 비용이 증가한다. Figure 8(b)는 이를 보여주며, 다른 항목인 scheduling비용 및 memory 관리 비용은 (b) one-to-one과 동일하다.
Figure 8(c)는 앞서 설명한 GRO 효율의 결과를 나타낸다. Flows 개수가 많을수록 skb당 size가 작은 쪽으로 많이 몰려있는 것을 확인할 수 있다. 사실 이 현상은 network 최대 대역폭을 치는 모든 시나리오에서 겪을 수 있다. 다만 (b) one-to-one 과 (c) incast는 flow 개수가 적어서 GRO 효율의 문제가 나타나지 않았을 뿐..
Other Components
다른 영향 요소는 다음 포스트에 이어서 작성~
네트워크 스택의 비용에 관한 이해 3
해당 게시글은 Sigcomm '21 Understanding Host Network Stack Overheads를 번역하여 정리한 글입니다. 이전 게시글 네트워크 스택의 비용에 관한 이해 1 네트워크 스택의 비용에 관한 이해 2 Traffic Pattern 외 고려
byeo.tistory.com


