
- Today
- Total
Byeo
bind system call 2 (__inet_bind) 본문
이전 포스트 (bind system call 1: __sys_bind)
https://byeo.tistory.com/entry/bind-system-call-1
bind system call 1 (__sys_bind)
BSD socket API에서 socket을 생성한 뒤에는 server-side 측에서 bind를 실행합니다. bind는 나의 ip:port를 socket과 연결하는 역할을 수행하죠. 이 번에는 BSD socket API중에서 bind를 분석해보려고 합니다. 이전
byeo.tistory.com
현재까지의 흐름도
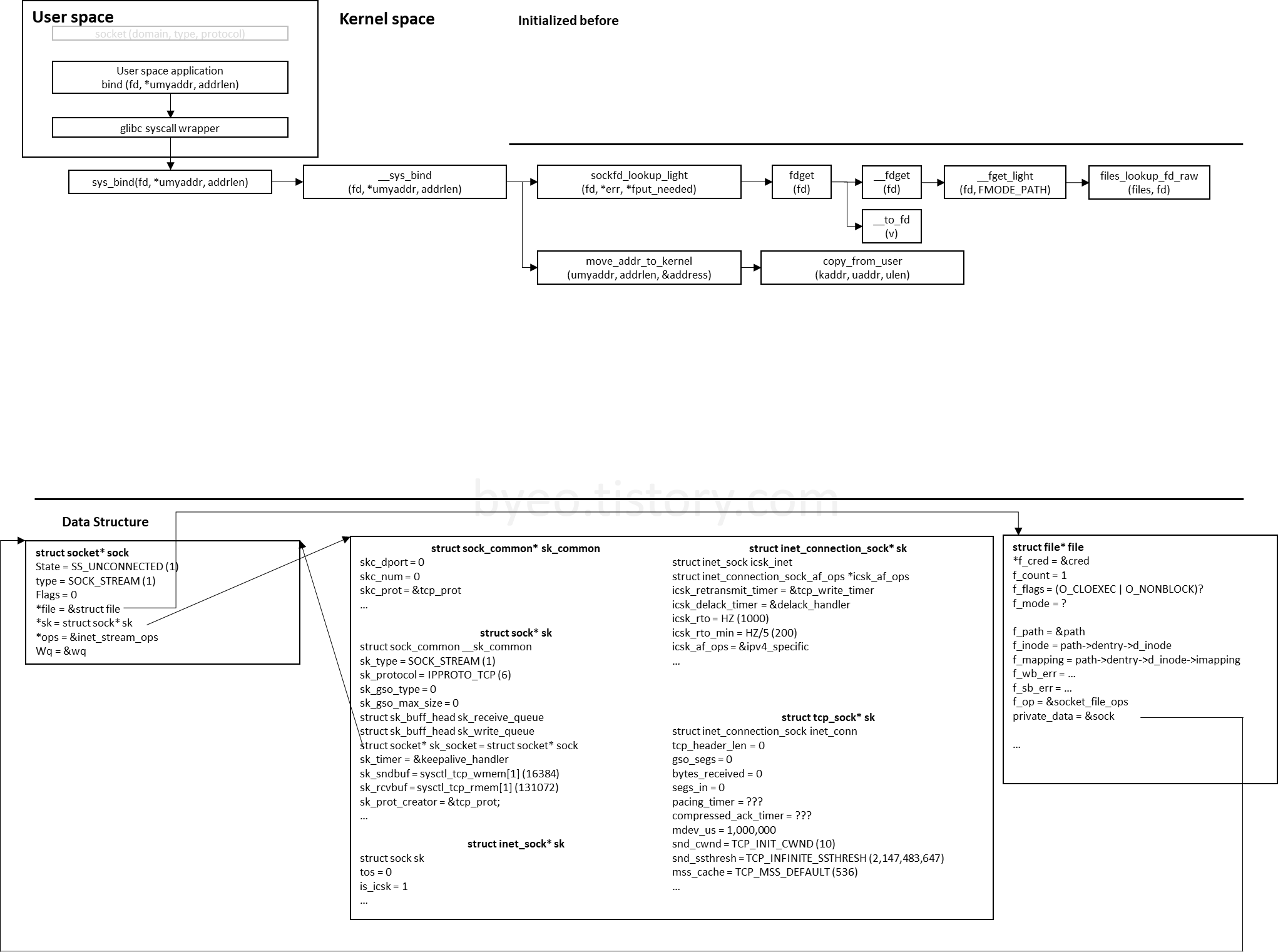
3. inet_bind
__sys_bind에서 그 다음으로 호출하는 함수는 sock->ops->bind였습니다.
// net/socket.c/__sys_bind() :1693
err = sock->ops->bind(sock,
(struct sockaddr *)
&address, addrlen);
우리는 socket system call을 살펴본 경험에서 이 함수가 inet_bind라는 것을 알고 있는데요. inet_bind를 이제 살펴봅시다.
// net/ipv4/af_inet.c/inet_bind() :438
int inet_bind(struct socket *sock, struct sockaddr *uaddr, int addr_len)
{
struct sock *sk = sock->sk;
u32 flags = BIND_WITH_LOCK;
int err;
/* If the socket has its own bind function then use it. (RAW) */
if (sk->sk_prot->bind) {
return sk->sk_prot->bind(sk, uaddr, addr_len);
}
if (addr_len < sizeof(struct sockaddr_in))
return -EINVAL;
/* BPF prog is run before any checks are done so that if the prog
* changes context in a wrong way it will be caught.
*/
err = BPF_CGROUP_RUN_PROG_INET_BIND_LOCK(sk, uaddr,
CGROUP_INET4_BIND, &flags);
if (err)
return err;
return __inet_bind(sk, uaddr, addr_len, flags);
}
EXPORT_SYMBOL(inet_bind);
이 함수에서 하는 역할은 sk->sk_prot->bind함수가 존재하는지 확인합니다. 존재하면 이로 갈음합니다.
위의 구조도를 참고해보면, sk->sk_prot는 &tcp_prot임을 알 수 있습니다. 하지만, tcp_prot 구조체를 직접 살펴보면 (net/ipv4/tcp_ipv4.c:3051) bind 함수는 정의되어있지 않습니다.
따라서 if에 걸리지 않아서 아래로 내려갑니다.
- BPF (Berkely Packet Filter)는 skip합니다.
결국 __inet_bind(sk, uaddr, addr_len, flags);를 호출하겠네요.
4. __inet_bind
인자는 sock에서 sk로 바뀌었고, uaddr, addr_len은 userspace가 준 값입니다. flags는 BIND_WITH_LOCK으로 넘어오겠네요.
__inet_bind함수는 깁니다..
// net/ipv4/af_inet.c/__inet_bind() :463
int __inet_bind(struct sock *sk, struct sockaddr *uaddr, int addr_len,
u32 flags)
{
struct sockaddr_in *addr = (struct sockaddr_in *)uaddr;
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
unsigned short snum;
int chk_addr_ret;
u32 tb_id = RT_TABLE_LOCAL;
int err;
if (addr->sin_family != AF_INET) {
/* Compatibility games : accept AF_UNSPEC (mapped to AF_INET)
* only if s_addr is INADDR_ANY.
*/
err = -EAFNOSUPPORT;
if (addr->sin_family != AF_UNSPEC ||
addr->sin_addr.s_addr != htonl(INADDR_ANY))
goto out;
}
tb_id = l3mdev_fib_table_by_index(net, sk->sk_bound_dev_if) ? : tb_id;
chk_addr_ret = inet_addr_type_table(net, addr->sin_addr.s_addr, tb_id);
/* Not specified by any standard per-se, however it breaks too
* many applications when removed. It is unfortunate since
* allowing applications to make a non-local bind solves
* several problems with systems using dynamic addressing.
* (ie. your servers still start up even if your ISDN link
* is temporarily down)
*/
err = -EADDRNOTAVAIL;
if (!inet_can_nonlocal_bind(net, inet) &&
addr->sin_addr.s_addr != htonl(INADDR_ANY) &&
chk_addr_ret != RTN_LOCAL &&
chk_addr_ret != RTN_MULTICAST &&
chk_addr_ret != RTN_BROADCAST)
goto out;
snum = ntohs(addr->sin_port);
err = -EACCES;
if (!(flags & BIND_NO_CAP_NET_BIND_SERVICE) &&
snum && inet_port_requires_bind_service(net, snum) &&
!ns_capable(net->user_ns, CAP_NET_BIND_SERVICE))
goto out;
/* We keep a pair of addresses. rcv_saddr is the one
* used by hash lookups, and saddr is used for transmit.
*
* In the BSD API these are the same except where it
* would be illegal to use them (multicast/broadcast) in
* which case the sending device address is used.
*/
if (flags & BIND_WITH_LOCK)
lock_sock(sk);
/* Check these errors (active socket, double bind). */
err = -EINVAL;
if (sk->sk_state != TCP_CLOSE || inet->inet_num)
goto out_release_sock;
inet->inet_rcv_saddr = inet->inet_saddr = addr->sin_addr.s_addr;
if (chk_addr_ret == RTN_MULTICAST || chk_addr_ret == RTN_BROADCAST)
inet->inet_saddr = 0; /* Use device */
/* Make sure we are allowed to bind here. */
if (snum || !(inet->bind_address_no_port ||
(flags & BIND_FORCE_ADDRESS_NO_PORT))) {
if (sk->sk_prot->get_port(sk, snum)) {
inet->inet_saddr = inet->inet_rcv_saddr = 0;
err = -EADDRINUSE;
goto out_release_sock;
}
if (!(flags & BIND_FROM_BPF)) {
err = BPF_CGROUP_RUN_PROG_INET4_POST_BIND(sk);
if (err) {
inet->inet_saddr = inet->inet_rcv_saddr = 0;
goto out_release_sock;
}
}
}
if (inet->inet_rcv_saddr)
sk->sk_userlocks |= SOCK_BINDADDR_LOCK;
if (snum)
sk->sk_userlocks |= SOCK_BINDPORT_LOCK;
inet->inet_sport = htons(inet->inet_num);
inet->inet_daddr = 0;
inet->inet_dport = 0;
sk_dst_reset(sk);
err = 0;
out_release_sock:
if (flags & BIND_WITH_LOCK)
release_sock(sk);
out:
return err;
}
0) Variable preparation
struct sockaddr_in *addr = (struct sockaddr_in *)uaddr;
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
unsigned short snum;
int chk_addr_ret;
u32 tb_id = RT_TABLE_LOCAL;
- *addr은 다시 userspace에서 사용했던 sockaddr_in으로 치환하는 것으로 보입니다. 여기서는 inet v4임을 확신할 수 있으므로 안전하죠. 또한, 바로 아래에서 AF_INET인지 검증합니다.
- *inet은 struct sock *sk를 inet_sock 구조체로 캐스팅합니다. socket system call에서 자주 봐서 익숙하죠 이제
- *net은 namespace를 가져오는 것으로 보입니다. socket system call에서 sk_alloc 함수 내에 sock_net_set(sk, net) (net/core/sock.c/sk_alloc() :1908)을 통해서 이루어집니다. 이 값은 (current->nsproxy->net_ns)입니다.
1) address family check
if (addr->sin_family != AF_INET) {
/* Compatibility games : accept AF_UNSPEC (mapped to AF_INET)
* only if s_addr is INADDR_ANY.
*/
err = -EAFNOSUPPORT;
if (addr->sin_family != AF_UNSPEC ||
addr->sin_addr.s_addr != htonl(INADDR_ANY))
goto out;
}
address family와 주소를 검증합니다. AF_INET이 아닌 경우, AF_UNSPEC과 관련해서 한번 더 체크하고 에러라면 함수를 빠져나옵니다. 사실 inet_bind인데 AF_INET외의 값이 들어오면 안되죠.
2) table lookup
// net/ipv4/af_inet.c:__inet_bind() :484
tb_id = l3mdev_fib_table_by_index(net, sk->sk_bound_dev_if) ? : tb_id;
chk_addr_ret = inet_addr_type_table(net, addr->sin_addr.s_addr, tb_id);
- l3mdev_fib_table_by_index 함수의 역할은 아직 이해하지 못했습니다. 확실한 것은 printk를 찍었을 때, tb_id의 값이 변화가 없었다는 점이었습니다.
2-1) inet_addr_type_table
inet_addr_type_table은 __inet_dev_addr_type을 호출합니다. 인자가 하나 추가되는데요, dev는 NULL로 호출합니다.
// net/ipv4/fib_frontend.c/__inet_dev_addr_type() :205
/*
* Find address type as if only "dev" was present in the system. If
* on_dev is NULL then all interfaces are taken into consideration.
*/
static inline unsigned int __inet_dev_addr_type(struct net *net,
const struct net_device *dev,
__be32 addr, u32 tb_id)
{
struct flowi4 fl4 = { .daddr = addr };
struct fib_result res;
unsigned int ret = RTN_BROADCAST;
struct fib_table *table;
if (ipv4_is_zeronet(addr) || ipv4_is_lbcast(addr))
return RTN_BROADCAST;
if (ipv4_is_multicast(addr))
return RTN_MULTICAST;
rcu_read_lock();
table = fib_get_table(net, tb_id);
if (table) {
ret = RTN_UNICAST;
if (!fib_table_lookup(table, &fl4, &res, FIB_LOOKUP_NOREF)) {
struct fib_nh_common *nhc = fib_info_nhc(res.fi, 0);
if (!dev || dev == nhc->nhc_dev)
ret = res.type;
}
}
rcu_read_unlock();
return ret;
}
if (ipv4_is_zeronet(addr) || ipv4_is_lbcast(addr))
return RTN_BROADCAST;
- ipv4_is_zeronet은 addr의 값이 0인지를 체크합니다. INADDR_ANY를 입력한다면 여기에 걸리겠네요.
- ipv4_is_lbcast는 addr이 INADDR_BROADCAST (0xffffffff)인지를 체크합니다. lbcast는 limited broadcast의 약자라고 합니다.
if (ipv4_is_multicast(addr))
return RTN_MULTICAST;- ipv4_is_multicast는 addr의 대역이 224.0.0.0/8 ~ 239.0.0.0/8에 해당하는지를 확인합니다.
- return (addr & htonl(0xf0000000)) == htonl(0xe0000000);
rcu_read_lock();
table = fib_get_table(net, tb_id);
if (table) {
ret = RTN_UNICAST;
if (!fib_table_lookup(table, &fl4, &res, FIB_LOOKUP_NOREF)) {
struct fib_nh_common *nhc = fib_info_nhc(res.fi, 0);
if (!dev || dev == nhc->nhc_dev)
ret = res.type;
}
}
rcu_read_unlock();
return ret;
fib_get_table을 호출하는군요.
2-2) fib_get_table
struct fib_table *fib_get_table(struct net *net, u32 id)
{
struct fib_table *tb;
struct hlist_head *head;
unsigned int h;
if (id == 0)
id = RT_TABLE_MAIN;
h = id & (FIB_TABLE_HASHSZ - 1);
head = &net->ipv4.fib_table_hash[h];
hlist_for_each_entry_rcu(tb, head, tb_hlist,
lockdep_rtnl_is_held()) {
if (tb->tb_id == id)
return tb;
}
return NULL;
}
tb_id가 0으로 주어진 경우에는 RT_TABLE_MAIN을 return합니다.
그 외의 경우에는 fib_table_hash를 순회하면서 tb_id (present in linux routing table)와 id가 일치하는 table이 있는지 확인하고 return합니다.
2-3) rt_class_t (짤막 routing table 내용 조사)
routing table number는 다음에 정의되어 있습니다.
// include/uapi/linux/rtnetlink.h :336
/* Reserved table identifiers */
enum rt_class_t {
RT_TABLE_UNSPEC=0,
/* User defined values */
RT_TABLE_COMPAT=252,
RT_TABLE_DEFAULT=253,
RT_TABLE_MAIN=254,
RT_TABLE_LOCAL=255,
RT_TABLE_MAX=0xFFFFFFFF
};
각 routing table에 대한 의미는 다음 link에 잘 정리되어 있었습니다.:
- http://linux-ip.net/html/routing-tables.html
- https://unix.stackexchange.com/questions/188584/which-order-is-the-route-table-analyzed-in
- https://medium.com/@marthin.pasaribu_72336/linux-policy-routing-introduction-37933f8cb62e
RT_TABLE_LOCAL은 Kernel이 직접 넣는 값으로 routing entry로서, local host 내에서의 통신들과 관련이 있습니다. (e.g., eth0에서 eth1로 보낸다던가.., eth0에서 broadcast한다던가...)
RT_TABLE_MAIN은 우리가 ip r 치면 보이는 바로 그 정보입니다.
RT_TABLE_DEFAULT는 MAIN 다음으로 보는 routing table입니다. 사실 이 table의 존재 의의는 아직 파악하지 못했습니다.
위 table들간의 우선순위는 ip rule에 출력됩니다.

2-4) fib_table_lookup
다시 __inet_dev_addr_type으로 돌아와서, fib_get_table에 성공하면 다음을 실행합니다.
// net/ipv4/fib_frontend.c/__inet_dev_addr_type() :223
ret = RTN_UNICAST;
if (!fib_table_lookup(table, &fl4, &res, FIB_LOOKUP_NOREF)) {
struct fib_nh_common *nhc = fib_info_nhc(res.fi, 0);
if (!dev || dev == nhc->nhc_dev)
ret = res.type;
}
fib_table_lookup 함수는 다음과 같습니다.
// net/ipv4/fib_trie.c/fib_table_lookup() :1431
/* should be called with rcu_read_lock */
int fib_table_lookup(struct fib_table *tb, const struct flowi4 *flp,
struct fib_result *res, int fib_flags)
{
struct trie *t = (struct trie *) tb->tb_data;
#ifdef CONFIG_IP_FIB_TRIE_STATS
struct trie_use_stats __percpu *stats = t->stats;
#endif
const t_key key = ntohl(flp->daddr);
struct key_vector *n, *pn;
struct fib_alias *fa;
unsigned long index;
t_key cindex;
pn = t->kv;
cindex = 0;
n = get_child_rcu(pn, cindex);
if (!n) {
trace_fib_table_lookup(tb->tb_id, flp, NULL, -EAGAIN);
return -EAGAIN;
}
#ifdef CONFIG_IP_FIB_TRIE_STATS
this_cpu_inc(stats->gets);
#endif
/* Step 1: Travel to the longest prefix match in the trie */
for (;;) {
index = get_cindex(key, n);
/* This bit of code is a bit tricky but it combines multiple
* checks into a single check. The prefix consists of the
* prefix plus zeros for the "bits" in the prefix. The index
* is the difference between the key and this value. From
* this we can actually derive several pieces of data.
* if (index >= (1ul << bits))
* we have a mismatch in skip bits and failed
* else
* we know the value is cindex
*
* This check is safe even if bits == KEYLENGTH due to the
* fact that we can only allocate a node with 32 bits if a
* long is greater than 32 bits.
*/
if (index >= (1ul << n->bits))
break;
/* we have found a leaf. Prefixes have already been compared */
if (IS_LEAF(n))
goto found;
/* only record pn and cindex if we are going to be chopping
* bits later. Otherwise we are just wasting cycles.
*/
if (n->slen > n->pos) {
pn = n;
cindex = index;
}
n = get_child_rcu(n, index);
if (unlikely(!n))
goto backtrace;
}
/* Step 2: Sort out leaves and begin backtracing for longest prefix */
for (;;) {
/* record the pointer where our next node pointer is stored */
struct key_vector __rcu **cptr = n->tnode;
/* This test verifies that none of the bits that differ
* between the key and the prefix exist in the region of
* the lsb and higher in the prefix.
*/
if (unlikely(prefix_mismatch(key, n)) || (n->slen == n->pos))
goto backtrace;
/* exit out and process leaf */
if (unlikely(IS_LEAF(n)))
break;
/* Don't bother recording parent info. Since we are in
* prefix match mode we will have to come back to wherever
* we started this traversal anyway
*/
while ((n = rcu_dereference(*cptr)) == NULL) {
backtrace:
#ifdef CONFIG_IP_FIB_TRIE_STATS
if (!n)
this_cpu_inc(stats->null_node_hit);
#endif
/* If we are at cindex 0 there are no more bits for
* us to strip at this level so we must ascend back
* up one level to see if there are any more bits to
* be stripped there.
*/
while (!cindex) {
t_key pkey = pn->key;
/* If we don't have a parent then there is
* nothing for us to do as we do not have any
* further nodes to parse.
*/
if (IS_TRIE(pn)) {
trace_fib_table_lookup(tb->tb_id, flp,
NULL, -EAGAIN);
return -EAGAIN;
}
#ifdef CONFIG_IP_FIB_TRIE_STATS
this_cpu_inc(stats->backtrack);
#endif
/* Get Child's index */
pn = node_parent_rcu(pn);
cindex = get_index(pkey, pn);
}
/* strip the least significant bit from the cindex */
cindex &= cindex - 1;
/* grab pointer for next child node */
cptr = &pn->tnode[cindex];
}
}
found:
/* this line carries forward the xor from earlier in the function */
index = key ^ n->key;
/* Step 3: Process the leaf, if that fails fall back to backtracing */
hlist_for_each_entry_rcu(fa, &n->leaf, fa_list) {
struct fib_info *fi = fa->fa_info;
struct fib_nh_common *nhc;
int nhsel, err;
if ((BITS_PER_LONG > KEYLENGTH) || (fa->fa_slen < KEYLENGTH)) {
if (index >= (1ul << fa->fa_slen))
continue;
}
if (fa->fa_tos && fa->fa_tos != flp->flowi4_tos)
continue;
if (fi->fib_dead)
continue;
if (fa->fa_info->fib_scope < flp->flowi4_scope)
continue;
fib_alias_accessed(fa);
err = fib_props[fa->fa_type].error;
if (unlikely(err < 0)) {
out_reject:
#ifdef CONFIG_IP_FIB_TRIE_STATS
this_cpu_inc(stats->semantic_match_passed);
#endif
trace_fib_table_lookup(tb->tb_id, flp, NULL, err);
return err;
}
if (fi->fib_flags & RTNH_F_DEAD)
continue;
if (unlikely(fi->nh)) {
if (nexthop_is_blackhole(fi->nh)) {
err = fib_props[RTN_BLACKHOLE].error;
goto out_reject;
}
nhc = nexthop_get_nhc_lookup(fi->nh, fib_flags, flp,
&nhsel);
if (nhc)
goto set_result;
goto miss;
}
for (nhsel = 0; nhsel < fib_info_num_path(fi); nhsel++) {
nhc = fib_info_nhc(fi, nhsel);
if (!fib_lookup_good_nhc(nhc, fib_flags, flp))
continue;
set_result:
if (!(fib_flags & FIB_LOOKUP_NOREF))
refcount_inc(&fi->fib_clntref);
res->prefix = htonl(n->key);
res->prefixlen = KEYLENGTH - fa->fa_slen;
res->nh_sel = nhsel;
res->nhc = nhc;
res->type = fa->fa_type;
res->scope = fi->fib_scope;
res->fi = fi;
res->table = tb;
res->fa_head = &n->leaf;
#ifdef CONFIG_IP_FIB_TRIE_STATS
this_cpu_inc(stats->semantic_match_passed);
#endif
trace_fib_table_lookup(tb->tb_id, flp, nhc, err);
return err;
}
}
miss:
#ifdef CONFIG_IP_FIB_TRIE_STATS
this_cpu_inc(stats->semantic_match_miss);
#endif
goto backtrace;
}
이 코드를 이해하려면 kernel의 trie자료구조와 그 자료구조를 다루는 매크로 함수들에 대해서 익숙해져야 할 것으로 보입니다. Kernel의 bitwise로 관리하는 trie 자료구조가 익숙치 않아서, 주석과 코드를 눈으로만 봤을 때의 구조를 해석하였습니다. fib_trie.c 코드와 더불어서 이 내용들은 다음에 기회가 되면 다루는 것으로 하겠습니다. 틀릴 수 있으니 유의
동작 원리는 크게 다음과 같은 과정으로 보입니다.
1. trie 자료구조를 root부터 끝까지 계속 파고 따라간다. 만약 leaf에 도달하면 이는 32bit address가 모두 일치한다고 볼 수 있으므로, Longest Prefix Match (LPM)이라고 볼 수 있다. 따라서 if (IS_LEAF(n))의 경우에는 goto found;
2. LEAF를 찾지 못했으면 step2 주석이 있는 반복문을 실행. 현 tnode에 있는 leaf들에 대해서 일치하는 node를 찾지 못했다면 부모로 한 단계 올라가서 조사
3. 정상적으로 찾았다면, res에 값들을 넣어서 함수를 종료한다.
// net/ipv4/fib_trie.c:fib_table_lookup() :1611
res->prefix = htonl(n->key);
res->prefixlen = KEYLENGTH - fa->fa_slen;
res->nh_sel = nhsel;
res->nhc = nhc;
res->type = fa->fa_type;
res->scope = fi->fib_scope;
res->fi = fi;
res->table = tb;
res->fa_head = &n->leaf;
2-5) fib_info_nhc
fib_table_lookup함수가 종료되어서 다시 __inet_dev_addr_type으로 돌아왔다면, 그 다음으로 실행되는 함수는 fib_info_nhc일 것입니다.
// net/nexthop.h :457
static inline struct fib_nh_common *fib_info_nhc(struct fib_info *fi, int nhsel)
{
if (unlikely(fi->nh))
return nexthop_fib_nhc(fi->nh, nhsel);
return &fi->fib_nh[nhsel].nh_common;
}
nhc는 nexthop common의 약자로, 구조체에는 device, address, flag 등이 담겨있습니다.
우리가 ip r로 칠 때 나온는 `nexthop via` 와 관련되어 보입니다. local routing table에서는 nexthop이 없으니 if (unlikely(fi->nh))에서 false가 되어 바로 return을 실행하겠군요.
2-6) __inet_dev_addr_type return
// net/ipv4/fib_frontend.c/__inet_dev_addr_type() :227
if (!dev || dev == nhc->nhc_dev)
ret = res.type;
}
}
rcu_read_unlock();
return ret;
}
dev는 NULL이므로 if문이 true가 되고, res = res.type을 지정할 것으로 보입니다.
2-7) __inet_dev_addr_type의 return value test



printk를 넣어서 테스트해보니, ret에는 위 사진처럼 다음과 같은 값이 들어갔습니다. 10.0.0.20만 실제 host에 존재하는 주소입니다.
- INADDR_ANY: 3 (RTN_BROADCAST)
- inet_addr("10.0.0.20"): 2 (RTN_LOCAL)
- inet_addr("8.8.8.8"): 1 (RTN_UNICAST)
- inet_addr("224.8.8.8"): 5 (RTN_MULTICAST)
2-8) fib table과 관련하여..
bind함수에서는 fib table을 조회만 합니다. fib local routing table에 entry가 추가되는 원인중에서 하나는 ip address add를 했을때로 보입니다. 즉, 우리는 fib table 추가 과정은 모른채로 보다보니 해당 코드에 알고있는 지식이 많이 없는데요. 언젠가는 공부를 해봐야겠습니다.
이 이후로는 다시 __inet_bind 함수로 돌아옵니다. 이 부분은 다시 다음 포스트에서 작성하겠습니다~
현재까지의 흐름도
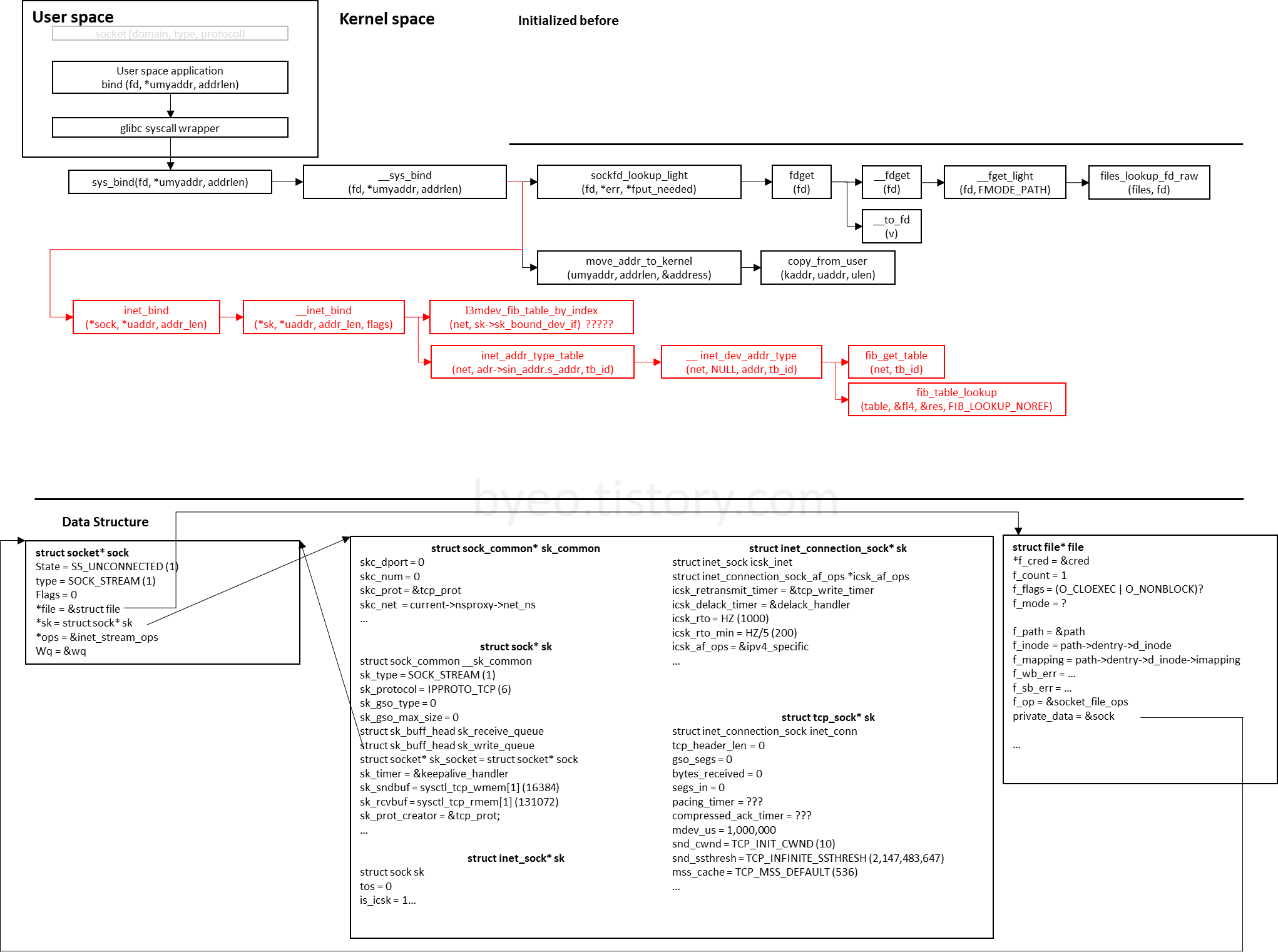
'프로그래밍 (Programming) > 네트워크 스택' 카테고리의 다른 글
| listen system call 1 (__sys_listen) (0) | 2024.05.11 |
|---|---|
| bind system call 3 (__inet_bind - 2) (0) | 2024.05.01 |
| bind system call 1 (__sys_bind) (0) | 2024.04.27 |
| BSD Socket API (0) | 2024.04.17 |
| socket system call 4 (sock_map_fd) (0) | 2024.04.14 |



